实践内容:索引
1. 索引篇
1.1. 普通索引、唯一索引
1.1.1. InnoDB引擎架构
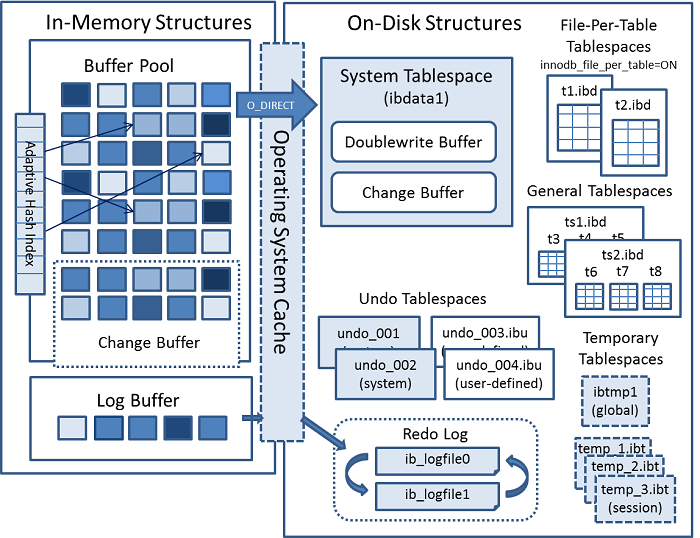
1.1.2. 查询过程
InnoDB中的索引是采用的B+树结构,包含主键索引(聚簇索引)、非主键索引(普通索引、唯一索引、关联索引),普通索引又具备最左前缀规则。
InnoDB中按数据页读写,每个数据页默认16KB,一个数据页包含多个记录,因此普通索引和唯一索引差异基本很低:
唯一索引,找到数据记录后,就停止继续往后搜索,而普通索引会继续找,直至第一个找到和条件不匹配的。
1.1.3. 更新过程
change buffer: 数据页在内存,找到记录更改内存;数据页没有在内存,先更新到change buffer,下次查询/定期进行内存Merge,再刷入磁盘!change buffer占用buffer pool的内存空间,可以通过innodb_change_buffer_max_size设置change buffer适用写多读少的场景,因为随机IO写操作被批量merge了,让才进行磁盘IO,若写入后,立马查询的场景,这样随机IO没有降低,反倒多了change buffer开销
唯一索引不能使用
change buffer,因为唯一索引必须要和数据页中的数据校对,因此数据页一定需要读入内存(因此也没有了change buffer的述求了),因此如果是唯一索引,会导致更大的磁盘IO开销综合看来,普通索引足够适用,特别是机械硬盘时代,对大表更新效果还是较为明显的(调大
change buffer容量)
1.1.4. 对比带changebuffer的查询和更新
- 更新过程:
- 更新页在内存中:
直接更新 - 更新页不在内存中:
写changebuffer - 将上述两处操作写
redolog(ib_log_fileX) - 后台异步写
系统表空间(ibdata1)和数据表空间(t.ibd)
- 更新页在内存中:
- 读取过程:
- 读取页在内存中:
直接读取 - 读取页不在内存中:
读入页数据到内存中,然后应用changebuffer中的操作日志,生成一个新版本返回
- 读取页在内存中:
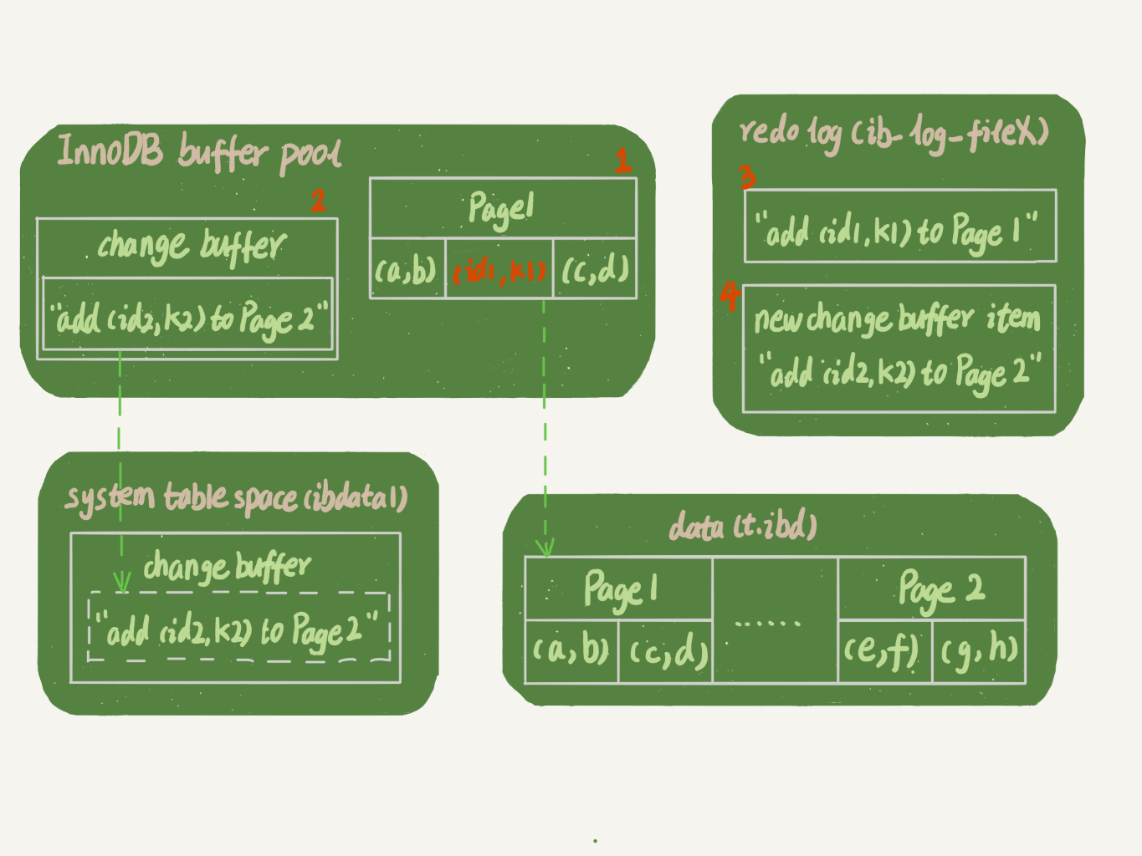
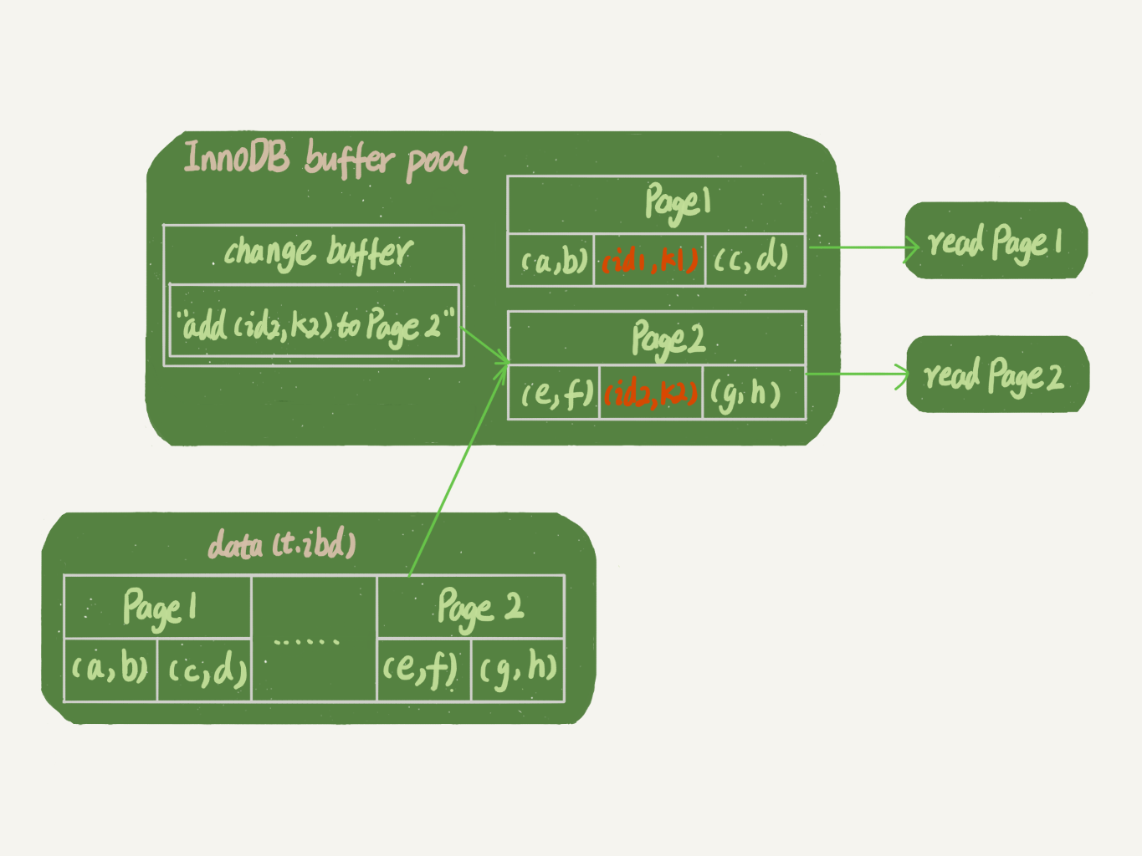
1.1.5. ChangeBuffer的Merge与RedoLog的WAL
change buffer中有Merge操作,redo log中有WAL机制,都是降低随机磁盘IO,但Merge是降低了读IO(不用立马随机IO读取数据页),WAL是降低了日志写IO(将多个redolog转成顺序写)
Merge的流程:
- 从磁盘读入数据页到内存(老版本)
- 从
ChangeBuffer找到数据页的Change记录,依次Merge得到新版本数据(产生内存脏页,后续被Mysql刷回磁盘) - 写入
redolog,包含了数据的变更和ChangeBuffer的变更
1.1.6. 唯一索引、普通索引的应用
- 业务需要数据库做强依赖,保证数据的唯一性
- 归档库表,考虑使用普通索引,优化磁盘IO
1.2. Mysql服务选取索引原理
1.2.1. 存储过程和函数的区别
两者可以实现类似的能力,但函数更偏向解决一个特定的问题,存储过程一般稍复杂,同时限制条件较少。
- 存储函数:不能用临时表、可以嵌入SQL执行、参数仅能为in(传值类型)、仅能返回一个结果值(RETURN返回)
- 存储过程:需要用CALL调用、支持结果集返回、参数支持in(传值方式)、out(结果返回)、inout(传址方式)
| |
两者的跟多信息:
help create procedure
1.2.2. 创建一个存储过程,往一个表中插入10万行记录
| |
1.2.3. 开启慢日志调试
| |
1.2.4. 优化器的逻辑
选择索引是优化器的工作,优化器除了扫描行、是否使用临时表、是否排序等综合考虑。
扫描行是通过统计(索引的区分度)估算记录数,当Cardinality基数越大,索引的区分度就越好,统计还会考虑回表的资源开销。
- 如果通过
explain发现实际行数差别太大,可以通过analyze table t修改 - 可以通过
force index(x)修正 - 可以通过修改SQL语句,引导优化器选择到正确的索引
- 创建一个更合适的索引,或删掉误用的索引
1.3. 给字符串加索引
1.3.1. 针对Email邮箱案例 - 前缀有差异
使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
确定我应该使用多长的前缀,依次执行不同的count比对差异:
1 2 3 4 5 6 7 8// 查询差异 select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, from user; // 更改email索引长度 alter table SUser add index index2(email(6));注意:使用前缀索引就用不上覆盖索引对查询性能的优化了,这也是你在选择是否使用前缀索引时需要考虑的一个因素。
1.3.2. 针对身份证案例 - 前缀雷同
使用倒序存储:每次存储之前反序存,读取的时候反序读取,索引照样添加,占用额外的CPU
新增一个hash字段冗余存储,占用额外存储空间,相比倒序更稳定(因为字符串有长有短)
1 2 3 4// crc32 alter table t add id_card_crc int unsigned, add index(id_card_crc); // 引用到hash列的索引 select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
1.4. 日志和索引相关问题
- 如果你创建的表没有主键,或者把一个表的主键删掉了,那么
InnoDB会自己生成一个长度为 6 字节的rowid来作为主键。
2. 主从数据一致性篇
2.1. Mysql怎么保证数据不丢
2.2. Mysql怎么保证主备一致
2.3. 读写分离有哪些坑
2.4. 主库出现问题,从库怎么办
2.5. 为什么从库延迟了几个小时
3. 故障分析篇
3.1. Mysql服务抖动 - Flsuh脏页
- 当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为
脏页。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为干净页 Flush脏页到磁盘的过程,可能就是导致SQL抖动的原因
3.1.1. 导致Flush磁盘IO的场景
redolog写满导致,[writepos, checkpoint],当wp追上cp时候,阻塞所有的写操作,同时cp会前进到cp’,此时会导致[cp, cp']中的脏页flush到磁盘- 系统
BufferPool可用内存容量不足,导致需要进行内存资源回收(脏页刷入磁盘),从而加大了磁盘IO压力 – 常态,注意控制脏页比率(过多脏页耗时、更新操作阻塞导致业务敏感) - Mysql服务异步Flush – 空闲操作
- Mysql服务关停 – 忽略
3.1.2. 控制脏页比率
- 正确地告诉InnoDB所在主机的IO能力(IOPS可以利用
fio测试):innodb_io_capacity参数 - 多关注脏页比例
Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total,不要让他接近75%
| |
3.2. 幻读问题
3.3. 饮鸩止渴
3.4. 表空间回收:表数据删除和表文件大小问题
简单的通过
DELETE语句删除,不能达到回收表空间效果,DROP TABLE可以达到回收表空间效果
3.4.1. 表数据存储以及空洞问题
innodb_file_per_tableOFF:表数据存放在系统共享表空间,和数据字典放一起ON:每个INNODB表数据单独存放以.ibd为后缀的文件中,MySQL 5.6开始,默认为ON
InnoDB数据以B+树存储数据组织,数据按页存储,注意区分数据页的复用和记录的复用- 记录复用:页表间的空洞部分
- 数据页复用:数据页中所有记录都清空掉了
- 如果相邻数据页中记录数很少,数据页利用率很低,系统会把两个相邻数据页进行
页合并 DELETE只是把记录的位置标记为可复用,但磁盘文件的大小不会变,导致形成空洞随机INSERT非顺序插入,也可能导致页分裂,在新页插入导致前一个数据页中存在空洞
- 把空洞填补,就可达到表搜缩的效果,即
重建表,即创建一个临时表,然后往临时表插入数据(数据顺序插入),5.6版本以后支持Online DDL(将更新记录记录到日志中,后续在新记录重放)alter table A engine=InnoDB即默认为alter table t engine=innodb,ALGORITHM=inplace;gh-os开源工具
- tmp_table和tmp_file
- 临时表是在
MySQL Server层做的,即alter table t engine=innodb,ALGORITHM=copy;,强制拷贝表,在Server层做 - 临时文件是在
InnoDB引擎做的,即alter table t engine=innodb,ALGORITHM=inplace;,属于inplace原地做的,需要效果磁盘空间,故1T的表、1.2T不能做inplace DDL
- 临时表是在
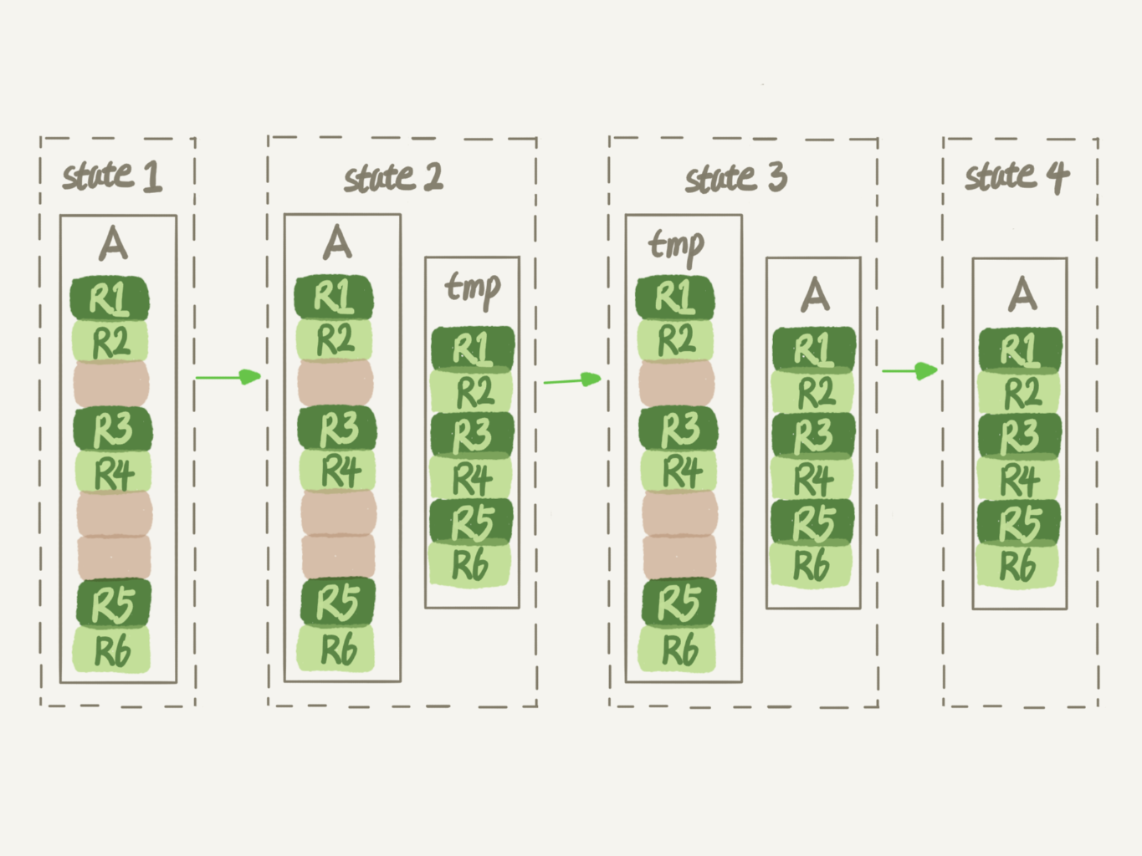
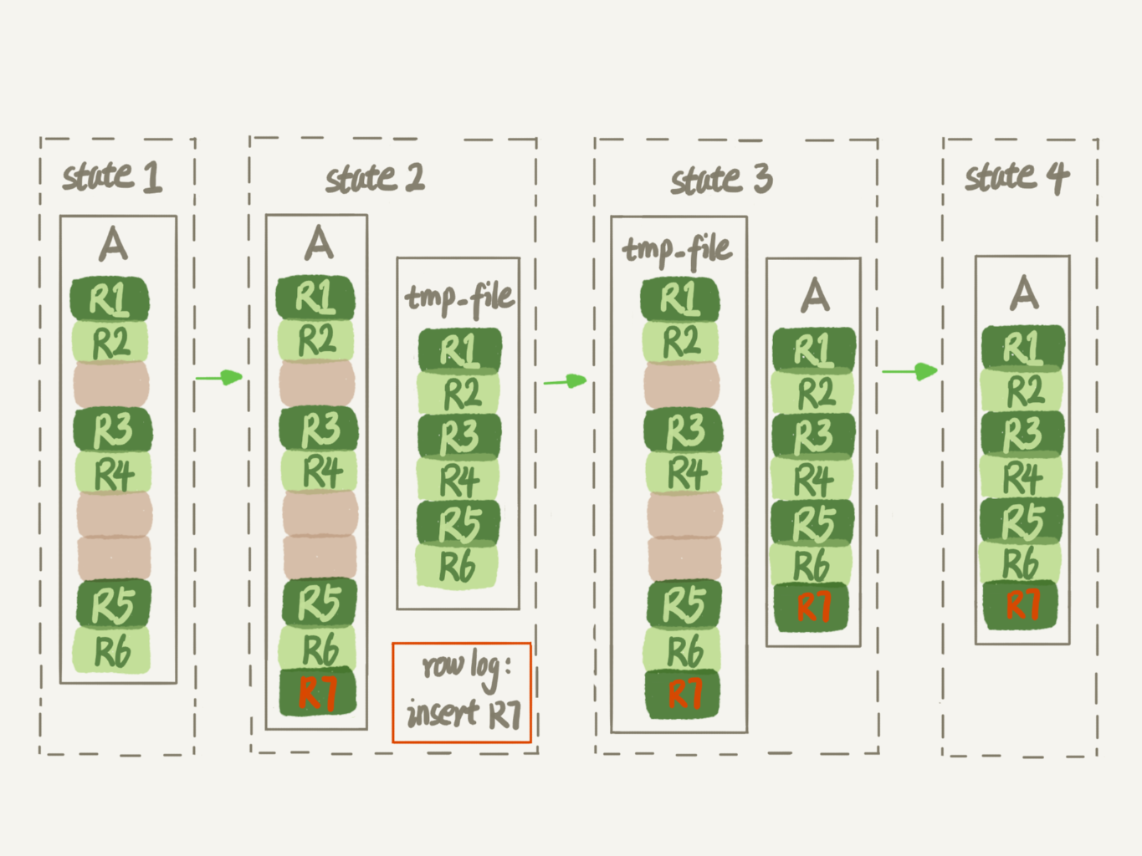
Tips: 重建方法都会扫描原表数据和构建临时文件,对于很大的表来说,这个操作是很消耗IO和CPU资源的,因此,如果是线上服务,要很小心地控制操作时间。如果想要比较安全的操作的话,可以采用开源的gh-ost 来做
另外,在重建表的时候,InnoDB 不会把整张表占满,每个页留了1/16给后续的更新用,也就是说,其实重建表之后不是“最”紧凑的。
3.4.2. optimize table、analyze table 和 alter table区别
alter table t engine = InnoDB:重建表(recreate table)analyze table t:对表的索引做重新统计,没有修改数据,期间加了MDL锁optimize table:等价于recreate+analyze
3.5. 为什么值改一行,锁了这么多
3.6. 为什么仅查询一行记录也很慢
3.7. 为什么相同逻辑的SQL语句性能差异很大
3.8. 如何判断Mysql是否出现问题了
3.9. 数据库删除了怎么办
3.10. 为什么有kill不掉的SQL
3.11. 查数据会不会撑爆数据库内存?
4. SQL篇
4.1. count(*)很慢
4.1.1. count的实现
- MyISAM,把表总行数记录在磁盘上,不加过滤条件返回很快,加了过滤条件也很慢了
- InnoDB,需要一行行的从引擎读取,然后累加计算,因为
MVCC存在,不能直接像MyISAM那样,存一个表记录整数;但InnoDB事务支持、并发能力、数据安全等都由于MyISAM
InnoDB是索引组织表,因此记录是哪个索引都可以统计,因此在保证正确逻辑下,MySQL优化器会找最小的那颗B+索引树来遍历。
在保证逻辑正确的前提下,尽量减少扫描的数据量,是数据库系统设计的通用法则之一。
注意show table status中的行是采样估算的,误差很大(50%),因此该行无法使用
有一个页面经常要显示交易系统的操作记录总数,到底应该怎么办呢?答案是,我们只能自己计数。 但如果使用其他缓存,比如Redis,则存在两个分布式存储数据不一致的情况,究其原因,主要是这两个不同的存储构成的系统,不支持分布式事务,无法拿到精确一致的视图;
4.1.2. 不同count(*)、count(id)、count(1)、count(字段)差别
InnoDB中,count()是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加,最后返回累计值。
count(字段): 返回满足条件结果集,且字段非NULl的count(*)、count(id)、count(1),返回满足条件结果集的总行数- count(主键id):引擎遍历整个表,把每行id取出,返回给server层;server层判断不能为空,按行累加
- count(1):引擎遍历整个表,不取值,返回给server层;server层对每行放一个数字“1”进去,按行累加;(快于
count(id),不用行数据解析) - count(字段):
- 字段定义为
非NULL,引擎遍历表取字段,断定不能为null,按行累加 - 自动定义为
NULL,引擎查询后,还需要判断字段是否为null,非null才累加
- 字段定义为
- Mysql性能优化差异:
- server层要什么,给什么
- InnoDB值给必要值
- 优化器仅做了
count(*)的取行数优化,
- 结论:
count(*) > count(1) > count(id) > count(字段) - 非NULl定义 > count(字段) - NULl定义,因此尽量使用count(*)即可!
4.2. order by是如何工作的
4.2.1. order by 语句执行过程
explain select city,name,age from t where city='杭州' order by name limit 1000 ;
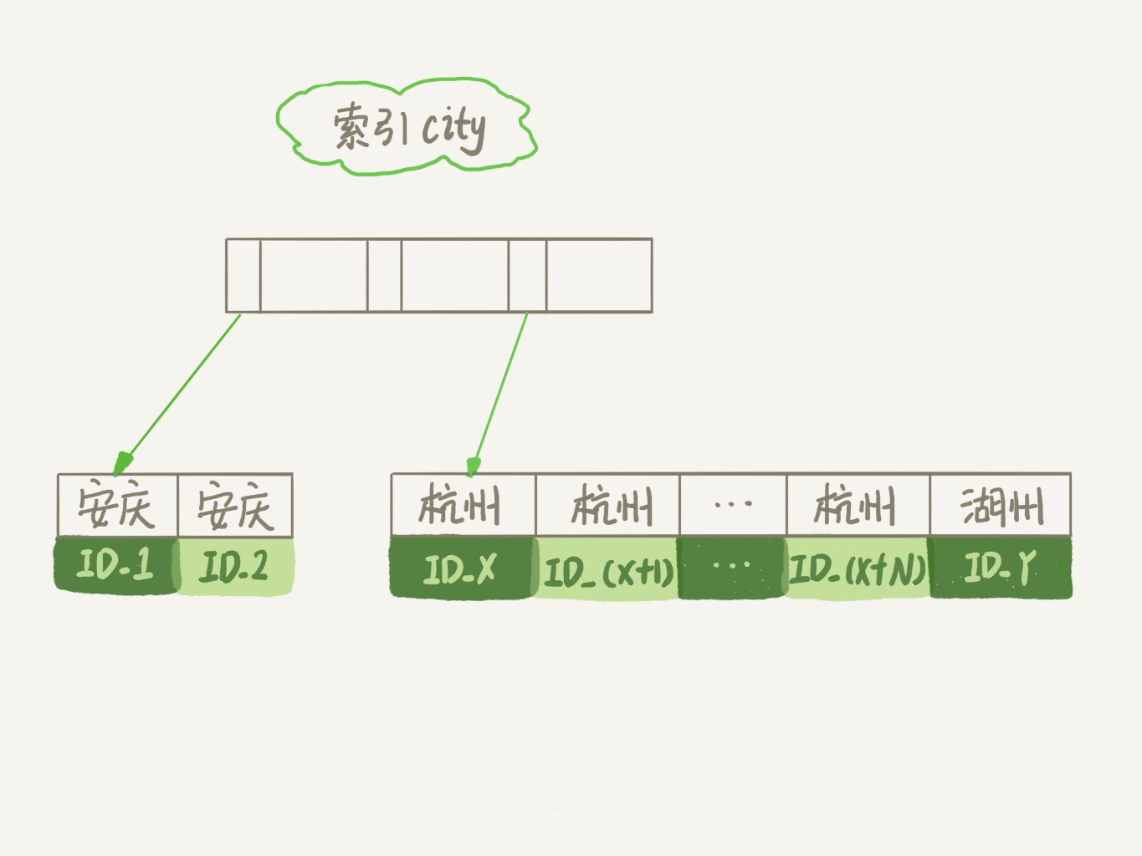
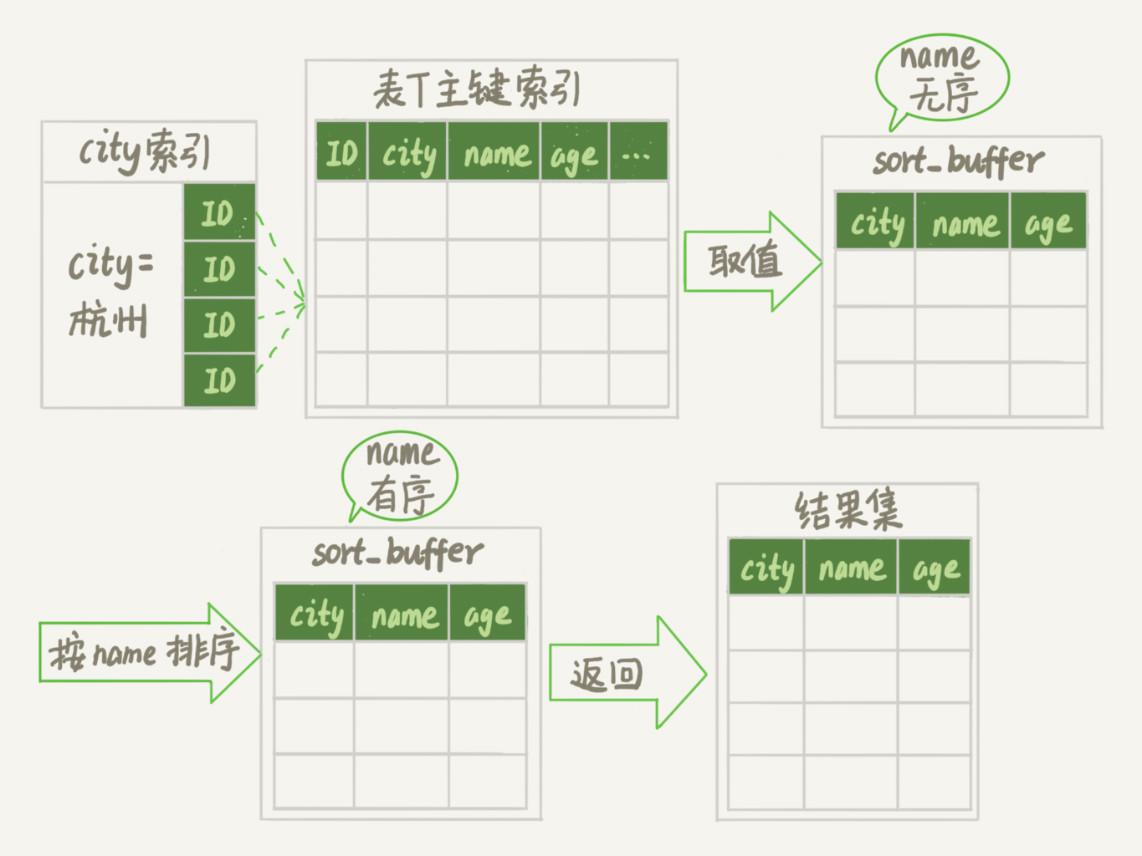
Extra这个字段中的Using filesort表示的就是需要排序,MySQL会给每个线程分配一块内存用于排序,称为sort_buffer。通常类似情况,我们会在city加索引,索引结构见后续图示;
- 初始化
sort_buffer,确定放入name、city、age这三个字段 - 从引擎中
city索引中查询到city=杭州的主键ID,回行查询name、city、age,存储到sort_buffer中 - 重复步骤2,直至
city!=杭州 - sort_buffer中的内容,按
name名称进行排序,sort_buffer中的内容排序,视排序的数据集规模和内存容量:- 内存放得下,但查询记录多用
快排 - 内存放得下,查询记录少用
堆排 - 内存放不下用
外部排序
- 内存放得下,但查询记录多用
- 基于排序结果取出前1000行内容返回给客户端
4.2.2. 全字段排序,当sort_buffer不足,需要做外排序
| |
| |
外排序(采用归并排序),可以通过优化器跟踪检测(如上);在排序过程中,只对原表的数据读了一遍,剩下的操作都是在sort_buffer和临时文件中执行的。
4.2.3. rowid排序,当排序内容过长
如果查询要返回的字段很多的话,那么sort_buffer里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
排序模式为rowid排序就是先利用主键ID和待排序字段name先排完后,再利用ID回表查询的过程(注意,最后取值为逻辑操作,即从之前的无序记录数据中直接找到对应ID的行);
对于InnoDB表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择, 但如果是内存表,则优化器忽略磁盘访问,优先采用rowid排序;

rowid排序,可以通过SET max_length_for_sort_data = 16;设置最大排序数据长度,当查询字段总长度超过该长度限制,将采用rowid排序
Mysql设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
4.2.4. 联合索引和覆盖索引,优化排序过程
- 因为联合索引,已经是有序的了,因此可以省略排序的时间。
- 比如联合索引
(city, name),在索引记录中是按city、name已排序好了,那么where city=x order by name就可以省略排序开销了 explain结果中Extra值没有了Using filesort了,仅为Using index condition
- 比如联合索引
- 因为覆盖索引,待查询内容已经在索引中了,因此可以省略了回表的操作,进一步得到了优化
explain结果中的Extra值为Using index
4.3. 如何正确线上随机内容
4.3.1. 通过存储过程批量插入单词
| |
4.3.2. order by rand() 流程
order by rand()使用了内存临时表,内存临时表排序的时候使用了rowid排序方法,可见相对流程复杂了很多:
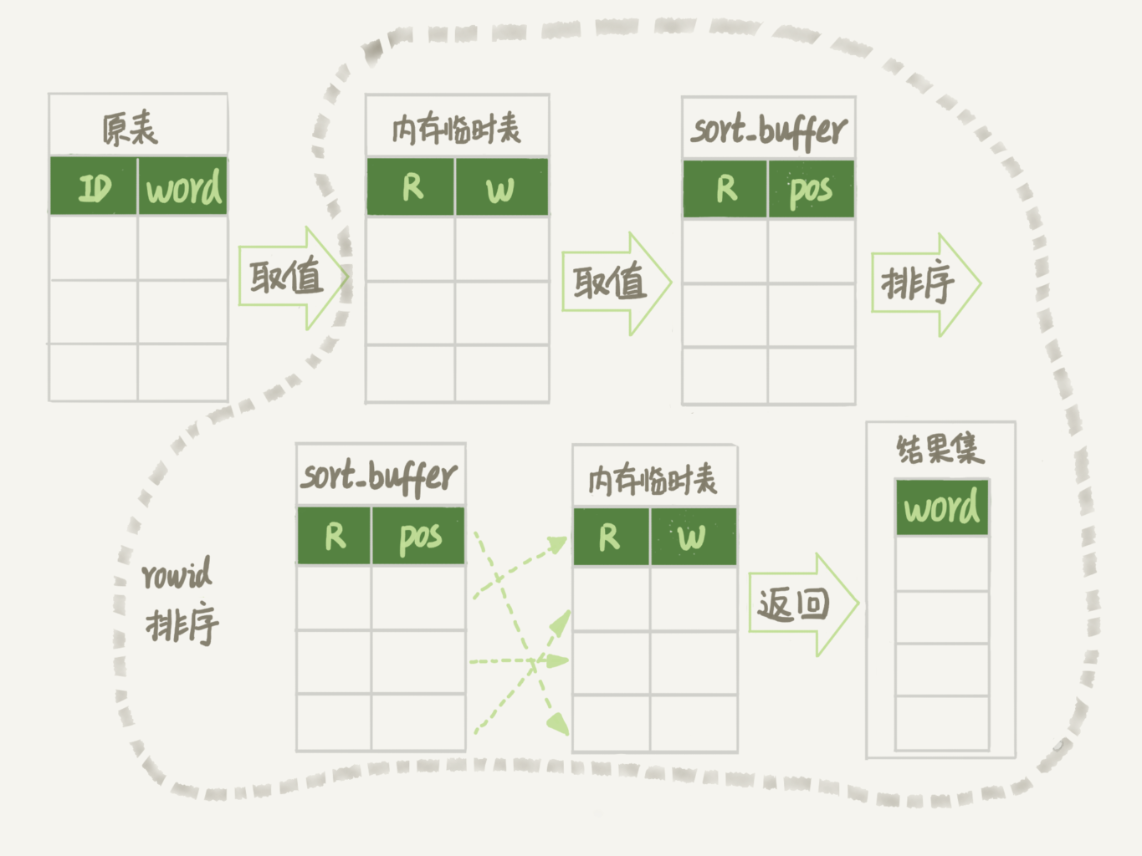
- 关于行记录唯一标识POS:
- 对于
有主键的rowid表来说,这个rowid=主键ID; - 对于
没有主键的InnoDB表来说,这个rowid=系统生成POS(6个字节长); MEMORY引擎不是索引组织表,可以认为它就是一个数组,这个rowid就是数组的下标;
- 对于
- 内存表阈值:
tmp_table_size- 当超过
tmp_table_size=16M大小后,内存表会转磁盘临时表
- 当超过
- 正确从数据库中获取随机记录做法:
- 取得表行数,记为C
- 根据相同随机算法,得到从[0, C]中取
Y1,Y2,Y3 - 执行指定次数的
limit Yx, 1
在实际应用的过程中,比较规范的用法就是:尽量将业务逻辑写在业务代码中,让数据库只做“读写数据”的事情。