这些命令是在开发或者运维配置过程中常用的一些命令,自己查找和记录下来不断完善!
1. 操作系统架构查阅
参考:
i386 32-bit intel
x86_64 64-bit intel
x86_64h 64-bit intel (haswell)
arm64 64-bit arm
arm64e 64-bit arm (Apple Silicon)
1
2
3
4
5
6
7
8
9
10
11
| # mac下查看
$ arch
arm64
# centos服务下查看
$ arch
x86_64
# alpine系统下
# arch
aarch64
|
2. man 文档不区分大小写搜索
执行export MANPAGER='less -I',在执行man tcp
在 man 手册内就不区分大小写搜索了
3. bash 下因为有配色,会导致批量 touch 失败
解决方法: ls --color=never取消颜色:
1
| for p in $(ls --color=never); do touch "$p"/.gitkeep; done
|
4. Linux 变量操作
4.1. 参数传递
$#: 脚本接收参数个数$*: 脚本接收参数字符串模式,比如 a.sh 1 2,则$*="1 2"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #!/bin/sh
echo "第1个参数为:$0";
echo "第1个参数为:$1";
echo "第2个参数为:$2";
echo '$#='$# # 参数个数
echo '$$='$$ # 脚本当前进程号
echo '$?='$? # 最后命令执行状态
echo '$*='$* # 参数字符串形式, $*="1 2 3"
echo '$@='$@ # 参数数组形式,支持循环迭代,$@=1 2 3
# $@可以被for循环迭代
for v in $@; do
echo "var=$v"
done
|
4.2. 数组变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| // 1. 数组变量定义
arr=(0 1 2)
arr=(
0
1
)
arr[0]=0
arr[1]=1
// 2. 数组变量读取
echo ${arr[0]}
echo ${arr[@]} # 读取数组中所有变量
// 3. 循环输出
for v in "$arr{@}"; do
echo $v
done
// 4. 高版本v4+,支持关联数组,即map形式
# Example 1
declare -A assArr=(
["k1"]="val1"
["k2"]="val2"
)
for i in "${!assArr[@]}"; do
printf "%s %s\n" "$i" "${assArr[$i]}"
done
# Example 2
# 1. tcloud_cvm_pay_gg_138 => 43.135.172.138
# 2. tcloud_tiny_full_gz_162 => 43.139.21.162
# 3. tcloud_cvm_full_gz_67 => 106.55.196.67
# 4. devcloud_cvm => 9.134.233.187
# 5. tcloud_tiny_full_sgp_200 => 43.156.8.200
# 6. devcloud_container => 9.135.17.5
declare -A ipMaps=(
# 包年包月
["tcloud_cvm_full_gz_67"]="106.55.196.67"
["tcloud_tiny_full_sgp_200"]="43.156.8.200"
["tcloud_tiny_full_gz_162"]="43.139.21.162"
# 按量计费
["tcloud_cvm_pay_gg_138"]="43.135.172.138"
# 开发机器
["devcloud_container"]="9.135.17.5"
["devcloud_cvm"]="9.134.233.187"
)
# 输出
i=1
for k in "${!ipMaps[@]}"; do
printf "%d. %-25s => %s\n" "$i" "$k" "${ipMaps[$k]}"
i=$((i + 1))
done
|
4.3. 单个变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 双引号使用变量,输出变量值
echo $var
echo ${var}
echo "$var"
echo "${var}"
// 单引号,不会转义
echo '$var'
// 删除变量
unset var1
// 只读变量
readonly var1
|
4.4. 变量删除与替换
1
2
3
4
5
| path=${PATH}
// 删除
echo ${path#/*:} # :符合取代文字的『最短的』那一个
echo ${path##/*:} ##:符合取代文字的『最长的』那一个
|
| 变量配置方式 | 说明 |
|---|
| ${变量#关键词} | 若变量内容从头开始的数据符合『关键词』,则将符合的最短数据删除 |
| ${变量##关键词} | 若变量内容从头开始的数据符合『关键词』,则将符合的最长数据删除 |
| ${变量%关键词} | 若变量内容从尾向前的数据符合『关键词』,则将符合的最短数据删除 |
| ${变量%%关键词} | 若变量内容从尾向前的数据符合『关键词』,则将符合的最长数据删除 |
| ${变量/旧字符串/新字符串} | 若变量内容符合『旧字符串』则『第一个旧字符串会被新字符串取代』 |
| ${变量//旧字符串/新字符串} | 若变量内容符合『旧字符串』则『全部的旧字符串会被新字符串取代』 |
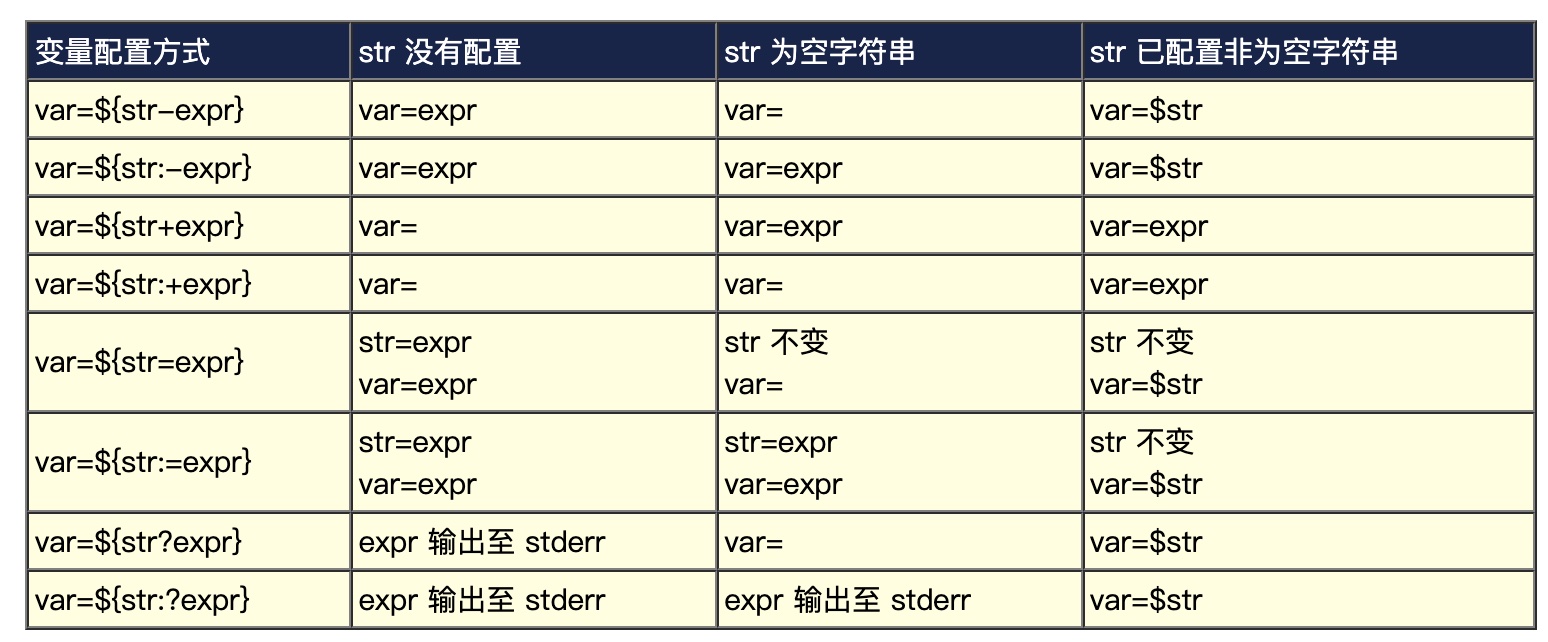
4.5. 变量内容替换
5. for 循环配合 ssh 操作
1
| for ip in "ip1" "ip2" "ip3"; do ssh -o StrictHostKeyChecking=no $ip 'ps -ef|grep sshd'; done
|
6. zip 和 unzip
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 打包(-r递归)
zip -r com.zip ./com
// 查看包内容
unzip -l com.zip
# 压缩指定文件
zip archive.zip file1 file2 file3
# -r 递归压栈目录以及包含文件,-x排除掉部分文件
zip -r mydir.zip mydir
zip -r mydir.zip mydir -x '*.log'
# -t 检测压缩文件是否正确
zip -t mydir.zip
# -u 更新压缩文件,仅压缩比原始文件新或修改的文件
zip -ru mydir.zip mydir
|
7. cat 从标准输入读取
1
2
3
4
5
6
7
8
9
| // 可以通过cat配合`<<`结合指定的标记比如EOF,END等,然后可以从标准输出读取
cat << EOF > fileB
// 输入json字符串,然后通过jq美化输出
cat << EOF|jq
实际效果就是:
cat << EOF
....
EOF
....
|
8. IP 列表生成
1
2
3
4
| // 列出 192.168.10.1 到 192.168.20的IP列表,放入$no_proxy_ips变量中
printf -v no_proxy_ips '%s,' 192.168.10.{1..20}
// 截掉末尾,输出
echo ${no_proxy_ips%,}
|
9. date 当前时间转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # 时间戳转日期
$ date --date=@1678678905
Mon Mar 13 11:41:45 CST 2023
# 转指定格式
$ date --date=@1678678905 +'%Y-%m-%d %H:%M:%S'
2023-03-13 11:41:45
# 获取指定日期时间的时间戳
$ date -d "2022-01-01 00:00:00" +%s
1640966400
# 获取当前时间戳
$ date +%s
1678678960
|
10. less 日志查看
作为日志查看,通常需要指定指定时间段的内容来
1
2
3
4
5
| // 查询指定时间段内的日志,利用awk设置起止时间,做处理
awk -vt1='16:29:50' -vt2='16:30:20' '{if ($2>t1 && $2<t2) print $0}' access.log
// 基于指定时间,按一定日期规则过滤access.log的日志,less -r标识用源色输出
awk -vt1=`date -d '16:29' +'%Y/%m/%d %H:%M:%S'` -vt2=`date -d '16:31' +'%Y/%m/%d %H:%M:%S'` '{if ($2>t1 && $2<t2) print $0}' access.log|less -r
|
11. grep 匹配指定单词、剔除不匹配操作
1
2
3
4
5
6
7
8
9
10
11
| // 先通过find找md的文件,寻找不匹配的
$ find . -name '*.md' -print0 | xargs -0 grep -iL "title"
// 和上面一样,上面的命令执行效率更优
$ find . -name '*.md' | xargs -n 1 grep -iL "title"
// 直接利用grep的-L,在仅包含md文件内寻找,不含title的文件
$ grep -iL "title" -r ./* --include '*.md'
// 匹配指定数字、单词,支持grep 在x.log文件中全量批量 241192数字,不附带其他更多的字符,但可以支持用引号包裹。比如 '241192'、241192、"241192"都匹配,但 241192322不匹配
$ grep -w '241192' x.log
|
12. 磁盘观测
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| // 磁盘IO观测, -d -x表示显示所有磁盘I/O的指标
$ iostat -d -x 1
%util ,磁盘I/O使用率;
r/s+ w/s ,就是 IOPS;
rkB/s+wkB/s ,就是吞吐量;
r_awai、+w_await ,就是读写等待响应时间。
rareq-sz 和 wareq-sz,平均读写请求的大小
// 进程IO观测
$ pidstat -d 1
秒读取的数据大小(kB_rd/s) ,单位是 KB。
每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
$ iotop
|
13. sar,系统活动报告
sar 支持提供系统的 CPU、内存、磁盘块设备、网络相关事件的报告
1
2
3
4
5
6
7
8
9
| $ sar -h
// CPU相关活动,包括软硬中断(vmstat、top、mpstat也可以比较好的看到)
$ sar -u ALL 1
// 网卡情况
$ sar -n DEV 1
$ sar -n IP 1
$ sar -n TCP 1
|
14. 打包命令
- -x:指示 tar 提取文件。
- -f:指定文件名/压缩包名称。
- -v:详细(提取文件时显示进度)。
- -j:通过 bzip2 过滤存档,用于解压缩.bz2 文件。
- -z:通过 gzip 过滤归档文件,用于解压缩.gz 文件。
- –wildcards:指示 tar 将命令行参数视为 glob 模式。
- –no-anchored:通知它模式在任何/分隔符之后适用于成员名称
14.1. 解压并仅提出部分文件
1
2
3
4
5
6
7
8
9
10
| // 先查看文件
$tar -ztf hugo.tar.gz
// 提取指定文件,注意-f的位置
$ tar -zxvf hugo.tar.gz hugo -C ./hugo/
$ tar -zx --extract hugo -f hugo.tar.gz
// 提取符合匹配符的文件
$ tar -zxvf hugo.tar.gz *go *.md -C ./hugo/
$ tar -zxf cbz.tar.gz --wildcards --no-anchored '*.php'
|
14.2. 利用管道传输压缩文件(压缩完,同传输给到另外一端解压)
1
2
3
4
5
6
7
8
9
10
11
| // 本地打包,同步传至远端服务cloud_native下的/tmp/mysql.tgz
tar -zvcf - mysql/ | ssh user@cloud_native -p 2222 "cat > /tmp/mysql.tgz"
// 可以利用括号写入多条命令
tar -zcvf - . |ssh user@cloud_native -p 2222 "(cd /data/www/archstat.com; tar -zxvf - )"
// 本地打包,同步到远端服务器,解压缩到指定/tmp目录,mysql目录,会在/tmp目录生成
tar -zvcf - ./mysql/ | ssh user@cloud_native -p 2222 "tar -zxvf - -C /tmp"
// 远程ssh执行打包,复制到本地
ssh user@tkstorm_srv -p 2222 "(cd /data/www/archstat.com; tar -zcf - ./mysql/)"|tar -zxf -
|
15. rpm 查询软件包配置
1
2
3
4
5
6
7
8
| // 前利用rpm -qa查看包名
rpm -qf postfix-2.10.1-7.el7.x86_64
// 查看配置
rpm -qc postfix-2.10.1-7.el7.x86_64
// 查看包相关文件
rpm -ql postfix-2.10.1-7.el7.x86_64
|
16. echo 进制转换
16.1. 转成 10 进制
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 利用printf函数,格式化输出
printf "%d\n" 0xFF
// bash
echo $((2#1111))
echo $((8#017))
echo $((16#FF))
// 或者
echo $((0x2f))
47
hexNum=2f
echo $((0x${hexNum}))
47
|
16.2. 转成 16 进制
17. find 文件查找
1
2
3
4
5
6
| // 查找非'*.c'的文件
find . \! -name "*.c" -print
// 查找并输出文件类型,并打印
find . -type f -exec echo {} \;
// 查找并执行删除命令
find -L /usr/ports/packages -type l -exec rm -- {} +
|
18. curl
18.1. curl 在 grep 时候,无法正常得到结果
因为 curl 将所有内容输出到标准错误输出接口导致,解决方式:
1
2
3
4
5
6
7
| // 将标准错误输出,转到标准输出,再grep
curl -Iv https://github.com 2>&1|grep -i '^http'
HTTP/1.1 200 OK
// 利用 --stderr 到 - ,也可以实现
curl -Iv --stderr - https://github.com|grep -i '^http'
HTTP/1.1 200 OK
|
18.2. proxy 代理或者指定 hostname 解析 ip 请求 url
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // Mac
curl -x socks5://10.33.1.196:1443 https://ip.cn
// CentOS
curl —socks5 127.0.0.1:10443 https://ip.cn
// 解析到指定机器
-4, --ipv4 Resolve name to IPv4 address
-6, --ipv6 Resolve name to IPv6 address
// 调试请求,注意`\`后面不要有空格
$ curl -I -k \
-H 'Host: tkstorm.com' \
-H 'cache-control: no-cache' \
-H 'user-agent: Test-UA' \
-H 'referer: https://haha.html' \
'https://119.23.74.167' \
--compressed
|
18.3. post 请求、cookie、get 参数、file 参数等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // 普通post参数(content-type: application/x-www-form-urlencoded)
curl -X POST \
'http://www.baidu.com/?value_1=a&value_2=b' \
-H 'cache-control: no-cache' \
-H 'content-type: application/x-www-form-urlencoded' \
-H 'cookie: SID=123&FId=456' \
-H 'keep-alive: true' \
-H 'postman-token: b8ad2446-1148-c94d-a42f-f1a8cfcd5297' \
-b 'SID=123&FId=456' \
-d 'uname=cocoglp&passwd=123456’
// 附带文件(content-type: multipart/form-data; boundary=xxx)
curl -X POST \
'http://www.baidu.com/?value_1=a&value_2=b' \
-H 'cache-control: no-cache' \
-H 'content-type: multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW' \
-H 'cookie: SID=123&FId=456' \
-H 'keep-alive: true' \
-H 'postman-token: aefb545b-6792-648f-6274-f9341ce6d86d' \
-b 'SID=123&FId=456' \
-F 'filea=@个人资料照片.jpg'
|
18.4. get 请求
1
2
3
4
| curl -X GET \
'http://www.baidu.com/?value_1=a&value_2=b' \
-H 'postman-token: 7f3cd841-c395-d518-a22d-0006db1265d7' \
-b 'SSID=12345&FROM_ID=307'
|
19. wget 和 curl 下载文件
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 自定义文件名
wget --content-disposition -c http://cn2.php.net/get/php-7.2.12.tar.gz/from/this/mirror
wget -O somefile.extension http://www.vim.org/scripts/download_script.php?src_id=9750
// -O使用远程名称,并-J强制-O从内容处置标头而不是URL获取该名称,并-L在需要时进行重定向。
-L, --location Follow redirects (H)
-J, --remote-header-name Use the header-provided filename (H)
-O, --remote-name Write output to a file named as the remote file
-S, --show-error
-s, --silent Silent mode
curl -JLO http://cn2.php.net/get/php-7.2.12.tar.gz/from/this/mirror
curl -sSL https://raw.githubusercontent.com/bitnami/bitnami-docker-kafka/master/docker-compose.yml > docker-compose-origin.yml
|
20. xargs
x argument 的意思,产生某个命令的参数的意思
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| // 选项与参数
-0 :如果输入的 stdin 含有特殊字符,例如 `, \, 空格键等等字符时,这个 -0 参数
可以将他还原成一般字符。这个参数可以用于特殊状态喔!
-e :这个是 EOF (end of file) 的意思。后面可以接一个字符串,当 xargs 分析到
这个字符串时,就会停止继续工作!
-p :在运行每个命令的 argument 时,都会询问使用者的意思;
-n :后面接数字,每次 command 命令运行时,要使用几个参数的意思。
// CentOS
-d :指定一个分隔符
-s :选择最大字符数
-I replace-str
// 加-p询问
cut -d':' -f1 /etc/passwd |head -n 3| xargs -p finger
// 加-n指定参数个数
cut -d':' -f1 /etc/passwd | xargs -p -n 5 finger
// 分隔符
echo "nameXnameXnameXname" | xargs -dX
name name name name
// 找到文件删除
find /tmp -name core -type f -print| xargs /bin/rm -f
find . -name '*.md'|xargs -n 1 ls -al
// 将要执行的内容,替换成字符变量
cat file | xargs -s 50000 echo | xargs -I {} -s 100000 rm '{}'
find . -name '*.md'|xargs -I '{}' -n 1 echo "md file >" '{}'
// 不加单引号也OK
// ps -ef|grep [a]utossh|awk '{print $2}'|xargs -I $ echo $
$ ps -ef|grep [a]utossh|awk '{print $2}'|xargs -I {} echo kill -15 {}
kill -15 26480
// 替换方式2,默认-i,就和-I {}雷同,所以可以直接-i不接,也可以-i[replace-str],不加空格的参数方式做替换(还是推荐选用-I {})
ps -ef|grep [a]utossh|awk '{print $2}'|xargs -i echo '{}'
ps -ef|grep [a]utossh|awk '{print $2}'|xargs -i$ echo '$'
// 备份Chrome的插件文件
cat /tmp/export.log|xargs -n 1 -I '$f' find $chrome_home -type d -name '$f' -exec cp -a '{}' /tmp/chrome_extensions \;
|
21. awk
BEGIN{...} PATTERN{...} END{...} ,BEGIN 和 END 部分都可以省略PATTERN{...}类似一个循环体,会对文件中的每一行进行迭代, $n 表示第 n 个字段,同时$0 表示整行- 相关预定义变量:
NF表示行字段数(num field),NR表示行记录数(num row)
21.1. BEGIN{}、PATTERN、END
1
2
3
4
5
6
7
8
9
| $ ls resources/images/2019/survey2018-results/fig*|awk 'END{print index($0, "fig")}'
42
// 每行前置计数i
awk 'BEGIN{ i=1 } { print i,$0 ; i++; }' index.html
// 打印每行
awk '{print}' index.html
// 统计文件行数
$ awk 'END{ print NR }' index.html
30
|
21.2. if 语句、循环等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // 正则操作,打印匹配以10开头的行
$ awk '{ if($0 ~ /10/){print $0;} }' index.html
// 指定分隔符
awk -F: '{ print $NF }' /etc/passwd
awk 'BEGIN{ FS=":" } { print $NF }' /etc/passwd
// 语句if.else;while;for...
awk 'BEGIN{
total=0;
for(i=0;i<=100;i++){
total+=i;
}
print total;
}'
|
21.3. awk 预定义变量字段
说明:[A][N][P][G]表示第一个支持变量的工具,[A]=awk、[N]=nawk、[P]=POSIXawk、[G]=gawk
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| $n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$0 这个变量包含执行过程中当前行的文本内容。
[A] FILENAME 当前输入文件的名。
[A] FS 字段分隔符(默认是任何空格)。
[A] NF 表示字段数,在执行过程中对应于当前的字段数。
[A] NR 表示记录数,在执行过程中对应于当前的行号。
[A] OFMT 数字的输出格式(默认值是%.6g)。
[A] OFS 输出字段分隔符(默认值是一个空格)。
[A] ORS 输出记录分隔符(默认值是一个换行符)。
[A] RS 记录分隔符(默认是一个换行符)。
[N] ARGC 命令行参数的数目。
[N] ARGV 包含命令行参数的数组。
[N] ERRNO 最后一个系统错误的描述。
[N] RLENGTH 由match函数所匹配的字符串的长度。
[N] SUBSEP 数组下标分隔符(默认值是34)。
[N] RSTART 由match函数所匹配的字符串的第一个位置。
[P] ENVIRON 环境变量关联数组。
[P] FNR 同NR,但相对于当前文件。
[G] ARGIND 命令行中当前文件的位置(从0开始算)。
[G] IGNORECASE 如果为真,则进行忽略大小写的匹配。
[G] FIELDWIDTHS 字段宽度列表(用空格键分隔)。
[G] CONVFMT 数字转换格式(默认值为%.6g)。
// 过滤掉首位行(尾行基于正则匹配识别)输出:
cat /data/www/pac.psr100.cn/proxy-default.pac |sed -n '/var blockHostsList/,/]/p'|awk '{if (NR>1 && $0 !~ /]/) print NR ":" $0}'
// grep匹配的内容,然后通过awk格式化输出
$ cat tmp.log|grep -oE '[0-9]+.*'|tr -d '\t'|awk '{printf "WHEN f_order_source=%d THEN \"%s\" \n", $1, $3}'
// 梳理数据库表字段: 按规则输出第1列,第2列到最后一列数据
// - 输出第1列加空格`(`: `printf "%s (", $1`
// - 输出第2到最后一列: `for (i=2;i<=NF;i++)printf("%s ", $i)`
// - `)`加换行: `print ")"`
$ cat order_table.log|awk '{printf "%s (", $1; for (i=2;i<=NF;i++)printf("%s ", $i); print ")"}'
|
21.4. gsub, substr, sprintf 等函数使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| // 字符串函数,比如substr、match、split、tolower等
// gsub, 在info中查找满足正则表达式,将数字替换`!`,并赋值给info
awk 'BEGIN{info="this is a test2010test!";gsub(/[0-9]+/,"!",info);print info}'
// substr
awk 'BEGIN{info="this is a test2010test!";print substr(info,4,10);}'
// sprintf
awk 'BEGIN{n1=124.113;n2=-1.224;n3=1.2345; printf("%.2f,%.2u,%.2g,%X,%on",n1,n2,n3,n1,n1);}'
// 从匹配<tr><td></td>的行起,在期内替换成数字i
$ cat index.html |awk 'BEGIN{i=0} {if (match($0, "<tr><td></td>")){i++;} gsub("<tr><td></td>", "<tr><td>"i"</td>", $0); print $0 }'
// 补齐表格内容
ls |sort -n -k 1.4|awk 'BEGIN{i=0; print "<table>\n<tr><td>ID</td><td>课程PPT</td></tr>"} {i++;if(NR>1){ line=sprintf("<tr><td>%d</td><td><a href=\"./%s\">%s</a></td></tr>", i, $0, $0); print line}} END{ print "</table>"}'
// awk函数使用
$ ls |sort -n -k 1.4|awk '{new=sprintf("%s %s%s%s%s", $1,$2,$3,$4,$5); gsub(/\s+$/,"",new); exec=sprintf("mv -i \"%s\" \"%s\" ", $0, new); system(exec)}'
|
21.5. gawk 示例
1
2
| // 通过match
grep keywords x.log|gawk 'match($0, /(token_type:TINY_USER_TOKEN_(WX|QQ))\s.*(app_version[^\s]+)\squa.*os=(.*)\/.*" > connection_id/, m) {printf "%s\t%s\t%s\n", m[3],m[1],m[4]}'|sort |uniq -c
|
22. sort 排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| // 开始排序的位置
echo "resources/images/2019/survey2018-results/fig"|wc -c
45
// 从第1列,45位置处开始排序, -n表示按number排序
// `1.n` refers to the nth character from the beginning of the line;
// if n is greater than the length of the line, the field is taken to be empty.
/data/www/tkstorm.com # ls resources/images/2019/survey2018-results/fig*|sort -k 1.45 -n
resources/images/2019/survey2018-results/fig1.svg
resources/images/2019/survey2018-results/fig2.svg
...
$ ls|sort -k 1.4 -n
lec1-课程概述-v1.pptx
lec2-实验零 操作系统实验环境准备-chy4.pptx
lec3-启动中断异常系统调用-chy1.pptx
lec4-lab1-chy1.pptx
lec5-第五讲 物理内存管理 连续内存分配-chy1.pptx
lec6-第六讲 物理内存管理 非连续内存分配-1.pptx
lec7-第七讲 实验二 物理内存管理.pptx
....
|
23. /dev/urandom生成随机字符串
1
2
3
4
5
6
7
8
9
10
11
12
| // 取10个字符
head -c10 /development/urandom|base64
// ascii随机字符
$ head -c 1000 /development/urandom|LC_ALL=C tr -dc 'a-zA-Z0-9@_'|fold -w 50|head -n 1
// base64字符集中随机字符
$ cat /development/urandom |base64 |head -c 50
// 基于dd方式
dd if=/development/urandom bs=512 count=1|LC_ALL=C tr -dc 'a-zA-Z0-9' |fold -w 50|head -n 1|cat
dd if=/development/urandom of=- bs=512 count=1|LC_ALL=C tr -dc 'a-zA-Z0-9' < -|fold -w 50|head -n 1|cat
|
24. sed - 删除字符串最后一个字符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| // 利用sed
echo 38252,38261,38269,|sed 's/,$//g'
// 变量截取
$ x=38252,38261,38269,; echo $x; echo ${x/%?/}
38252,38261,38269,
38252,38261,38269
// 以行为单位的新增(a|i)/删除功能(d)
nl /etc/passwd | sed '2,5d'
nl /etc/passwd | sed '2a drink tea' //第2行后加字符
nl /etc/passwd | sed '2i drink tea' //第2行之前加字符
// 以行为单位的替换(c)与显示功能(p)
nl /etc/passwd | sed '2,5c No 2-5 number' //将2到5行,替换成指定字符
nl /etc/passwd | sed -n '5,7p' // 打印5到7行,(-n)表示安静模式,仅5到7行内容
// 搜索&替换
sed 's/要被取代的字串/新的字串/g'
sed 's/^.*addr://g' | sed 's/Bcast.*$//g'
// 将匹配的空白行删除
sed '/^$/d'
// 直接修改(i),Tips: 注意会直接写原文件
sed -i 's/\.$/\!/g' regular_express.txt //每一行结尾若为.则换成 !
sed -i '$a # This is a test' regular_express.txt //最后一行加入『# This is a test』
// 利用sed去除行首、行尾、所有空格
sed 's/^[ \t]*//g'
sed 's/[ \t]*$//g'
sed 's/[ \t]//g'
$ echo " 12345 a b c"|sed 's/[1-9 \t]//g'
abc
// mac下的sed尝试删除出行首
sed -e 's/[[:space:]]//g'
|
25. uuid 生成
参考:https://serverfault.com/questions/103359/how-to-create-a-uuid-in-bash?rq=1
1
2
3
4
5
6
7
| // 基于库函数生成
uuidgen
// 基于urandom方式生成
od -x /development/urandom | head -1 | awk '{OFS="-"; srand($6); sub(/./,"4",$5); sub(/./,substr("89ab",rand()*4,1),$6); print $2$3,$4,$5,$6,$7$8$9}'
$ od -x /development/urandom | head -1 | awk '{OFS="-"; print $2$3,$4,$5,$6,$7$8$9}'|tr '[a-z]' '[A-Z]'
$ od -x /development/urandom | head -1 | awk '{OFS="-"; print $2$3,$4,$5,$6,$7$8$9}'|LC_ALL=C tr '[a-z]' '[A-Z]'
|
26. dns 查询
1
2
3
4
5
6
7
8
9
| // dns跟踪
dig +trace +nodnssec www.tkstorm.com
dig +short www.tkstorm.com
// dns调试
nslookup -debug tkstorm.com
// 解析耗时
time nslookup qq.com
|
27. mtr - 网络丢包分析
mtr(My traceroute)几乎是所有 Linux 发行版本预装的网络测试工具。其将 ping 和 traceroute 的功能合并,所以功能更强大。
mtr 默认发送 ICMP 数据包进行链路探测。您也可以通过“-u”参数来指定使用 UDP 数据包进行探测。
相对于 traceroute 只会做一次链路跟踪测试,mtr 会对链路上的相关节点做持续探测并给出相应的统计信息。
所以,mtr 能避免节点波动对测试结果的影响,所以其测试结果更正确,建议优先使用。
1
2
| yum install mtr
mtr tkstorm.com
|
28. lsof - 查看进程端口
支持基于端口快速查找进程方式:lsof、netstat,注意需要 ROOT 权限
28.1. MAC 环境 lsof
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| # -i 指定任何网络监听地址,支持一系列参数, -n 非字符串协议显示端口
# 支持: [46][protocol][@hostname|hostaddr][:service|port]
sudo lsof -n -i 4TCP
sudo lsof -n -i 4TCP:12639
sudo lsof -n -i :12639
# lsof -i 和internet网络相关,和 `netstat -a -p`雷同
lsof -i tcp:3000
lsof -ti:3000
# 进程编号
sudo lsof -p '123,^456'
# TCP、UDP协议状态
# Some common TCP state names are: CLOSED, IDLE, BOUND, LISTEN, ESTABLISHED, SYN_SENT, SYN_RCDV, ESTABLISHED, CLOSE_WAIT, FIN_WAIT1, CLOSING, LAST_ACK, FIN_WAIT_2, and TIME_WAIT.
sudo lsof -iTCP -sTCP:LISTEN -n
sudo lsof -iUDP -sUDP:Idle
// -n 不解析主机名 -P 不解析端口名
// -i 指定(indicate)IP版本,传输协议,端口列表等,注意顺序!!
// -i i select by IPv[46] address: [46][proto][@host|addr][:svc_list|port_list]
lsof -nP -i 4TCP
// COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
$ lsof -nP -i 4TCP |grep 8080
// Linux环境
netstat -ntap|grep 8000
lsof -i:19002
lsof -np 12421|grep '11.187.xx.xx'
|
29. perf - 动态追踪工具
1
2
3
4
5
| perf top
perf record -g
perf report
|
30. strace - 进程执行跟踪
命令说明:
- -tt: 精确到毫秒
- -T: 显示系统调用时间:Show the time spent in system calls.
- -c: 统计信息,统计过程不会打印相关输出明细(可以通过
-C优化) - -C: 持续统计信息,类似
-c,调用时间、次数、错误等信息,打印规则输出; - -v: 不缩写打印结构体相关成员内容
- -s: 指定最大字符串打印长度(默认是 32,这个当数据太少,不好判断的时候可以调大)
- -e expr: 告知 strace 跟踪哪些事件,以及如何跟踪这些事件,如
- -e trace=open,close,read,write 跟踪指定的 IO 系统调用
- -e trace=file 文件操作相关,比如 open,stat,chmod,unlink,….
- -e trace=process 进程相关
- -e trace=network 网络相关
- -e trace=signal 信号相关
- -e trace=ipc 所有 IPC 进程通信相关
- -e trace=desc 文件描述符操作相关
- -e trace=memory 内存操作相关
- -e abbrev=all|none|sets 默认是缩写所有大的结构体成员,通过
-v可以释放掉该效果,或者设置为none,或者指定成员 - -e verbose=all|none|sets 详细化打印结构体成员
- -e raw=set 使用未经过编码的参数打印系统调用参数
- -e signal=all|set 打印指定信号
- -e read=set 打印读取指定文件描述符的数据内容
- -e write=set 打印写入指定文件描述符的数据内容
- -o file: 打印输出记录到文件,而非标准错误输出
- -p pid1,pid2…: 跟踪指定进程号进程
- -f : 跟踪进程的子进程(通过 fork\vfork\clone 生成的)
- -ff: 和
-o filename配合,生成filename.pid按进程号区分的文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| // 短小快速分析
strace -tt -p 6,7
// 希望看到系统调用时间,加上`-T`
strace -ttT -p 6,7
// 希望看到更明细的参数信息`-s 1024`
strace -ttT -s 1024 -p 6,7
// 【足够详细】希望看到相关结构体成员信息`-v`
strace -ttTv -s 1024 -p 6,7
// 仅关系网络|进程|内存相关
strace -ttTvf -e trace=network -p 6,7
strace -ttTvf -e trace=process -p 6,7
strace -ttTvf -e trace=memory -p 6,7
// 希望加`-C`统计分析
strace -ttTCv -s 1024 -e trace=all -p 59432
strace -ttTCv -s 1024 -e trace=all -p 59432 -o /tmp/bench-all-1.log
strace -ttTCv -s 1024 -e trace=network,procss,desc -p -o /tmp/bench-net-proc-desc-1.log
strace -ttTfC -s 1024 -p "281590 279290 279157 279068 278854 278353" -o /tmp/bench-1106.log
strace -ttTfC -e trace=all -s 1024 -p "37912 37911 37910 37909 37908" -o /tmp/bench-1107.log
strace -ttTfC -e trace=all -s 1024 -p "`pidof php-fpm|awk '{print $1}'`" -o /tmp/bench-1108-01.log
// 调试nc进程(C/S模式),经典的Unix网络套接字编程中的内容可见!
strace -vCTtt nc -vl 1234 //服务端端
strace -vCTtt nc localhost 1234 //客户端
|
31. manpage 缺失问题
在 Docker 中,可能我们想安装 Man,但发现安装不了的情况,可以检查下包管理工具安装属性(为了镜像大小将 man 文件选择不安装):
1
2
3
4
5
6
7
8
| // 注释掉nodocs:
sed -i 's/tsflags=nodocs/# &/' /etc/yum.conf
// 重新安装需要man的包
yum reinstall shadow-utils
// 或者直接执行
yum --setopt=tsflags='' reinstall shadow-utils
|
32. yum 包安装处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| // 查询yum包内容,先安装yum-utils包
yum install yum-utils -y
// 利用repoquery -ql 包名查询
# repoquery -ql containerd.io.x86_64
/etc/containerd
/etc/containerd/config.toml
/usr/bin/containerd
/usr/bin/containerd-shim
/usr/bin/containerd-shim-runc-v1
/usr/bin/containerd-shim-runc-v2
/usr/bin/ctr
/usr/bin/runc
/usr/lib/systemd/system/containerd.service
/usr/share/doc/containerd.io-1.6.6
/usr/share/doc/containerd.io-1.6.6/README.md
/usr/share/licenses/containerd.io-1.6.6
/usr/share/licenses/containerd.io-1.6.6/LICENSE
/usr/share/man/man5/containerd-config.toml.5
/usr/share/man/man8/containerd-config.8
/usr/share/man/man8/containerd.8
/usr/share/man/man8/ctr.8
|
33. nc 命令
- 有时候服务器没有 telnet,我们可以通过
nc工具替代; - 有时候用于测试 TCP 的 C/S 模式也可以采用
nc替换:nc -l -p 1234和nc localhost 1234; - 数据传输+
shasum校验(linux 传完会自动断开),当然如果由scp、rsync等工具另做别论 - 正向代理
Tips: Linux 下的 nc 和 Mac 下的 nc 命令有一定差异,比如:nc -lv 1024(linux 下)表示在 1024 端口下监听,而在 Mac 下,需要通过-p指定监听端口
33.1. nc - 端口扫描
- -v 明细
- -z Zero-I/O mode (scanning)
- -w second 超时设置
1
2
3
4
5
6
7
8
| // 检测9000端口是否打开
nc -zv localhost 9000
// 批量扫描端口(比较耗时)
$ nc -zv 10.40.2.181 1-65535
static.io [10.40.2.181] 22 (ssh) open
static.io [10.40.2.181] 80 (http) open
...
|
33.2. nc - 数据传输
以下内容利用nc将 Mac 端的数据传输给到 Linux 端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| // 1. Mac端(客户端)计算待发送的数据shasum值
$ shasum go1.13.3.src.tar.gz
1fdfd1586888d4d24f5dadee6016092f89e6049e go1.13.3.src.tar.gz
// 2. Linux(服务端)充当数据接收方,接收到的数据存储到指定位置(Tips: CentOS下的nc没有指定`-p`参数)
nc -vl 1024 > /tmp/go1.13.3.src.tar.gz
// 3. Mac端(客户端):数据发送方,将文件加入的nc网络输入流中
nc -v 10.40.2.181 1024 < go1.13.3.src.tar.gz
// 4. Linux端(服务端),当数据传输完后,利用sha1sum计算数据的完整性(Tips: Linux上使用的sha1sum、md5sum均可以用于数据一致性校验, Mac下采用shasum和md5命令计算)
$ md5 go1.13.3.src.tar.gz
MD5 (go1.13.3.src.tar.gz) = 94ae8bf6a4fe623e34cb8b0db2a71ec0
$ shasum go1.13.3.src.tar.gz
1fdfd1586888d4d24f5dadee6016092f89e6049e go1.13.3.src.tar.gz
[root@test_10 tmp]# md5sum go1.13.3.src.tar.gz
94ae8bf6a4fe623e34cb8b0db2a71ec0 go1.13.3.src.tar.gz
[root@test_10 tmp]# sha1sum go1.13.3.src.tar.gz
1fdfd1586888d4d24f5dadee6016092f89e6049e go1.13.3.src.tar.gz
|
33.3. nc - 目录拷贝
如果传递的是目录,可以先对数据内容进行打包压缩,输出到 nc 网络连接上:
1
2
3
4
| // 接收端
nc -l -p 1234|uncompress -c|tar xvfp -
// 发送端
tar cfp - /some/dir|compress -c |nc -w 3 10.40.2.181 1234
|
33.4. nc - HTTP 请求
- 注意 echo 需要开启反斜杠转移,即
-e,注意HTTP1.0在每次 HTTP 请求后都会关闭连接,但HTTP1.1不会 - 另外在 HTTP1.1 类似管道发送多个 HTTP 请求时候,HTTP 是基于 TCP 上面的,不能随意发送多余的字符,否则引起 HTTP 协议解析失败产生 400 客户端错误!
1
2
3
4
5
6
| printf "GET / HTTP/1.0\r\n\r\n"|nc host.example.com 80
// echo
echo -e "HEAD / HTTP/1.0\r\n\r\n"|nc localhost 80
echo -e 'HEAD / HTTP/1.1\r\nHost:localhost\r\n\r\nHEAD /xx.html HTTP/1.0\r\n'|nc localhost 80
echo -e 'HEAD / HTTP/1.0\r\nHost:localhost\r\n\r\nHEAD /xx.html HTTP/1.0\r\n'|nc localhost 80
|
34. rsync 和 sync - 同步数据
1
2
3
4
5
| // rsync方式同步
rsync -avz -e "ssh -p 2222" ./* username@archstat.com:/tmp
// scp方式同步
scp -r -P 2222 ./* username@archstat.com:/tmp
|
35. stty 命令行 tty 相关快捷键
eof : End of file 的意思,代表『结束输入』。
erase : 向后删除字符,
intr : 送出一个 interrupt (中断) 的讯号给目前正在 run 的程序;
kill : 删除在目前命令列上的所有文字;
quit : 送出一个 quit 的讯号给目前正在 run 的程序;
start : 在某个程序停止后,重新启动他的 output
stop : 停止目前屏幕的输出;
susp : 送出一个 terminal stop 的讯号给正在 run 的程序。
(tips:是否有过把ctrl+S后,发现命令行无法输出的情况? 实际是停止了屏幕的输出,可以通过ctrl+Q恢复)
1
2
3
4
5
6
| [root@www ~]# stty -a
speed 38400 baud; rows 24; columns 80; line = 0;
intr = ^C; quit = ^\; erase = ^?; kill = ^U; eof = ^D; eol = <undef>;
eol2 = <undef>; swtch = <undef>; start = ^Q; stop = ^S; susp = ^Z;
rprnt = ^R; werase = ^W; lnext = ^V; flush = ^O; min = 1; time = 0;
...
|
36. set - 设置 bash 调试相关信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| // 调试相关,可以显示更多的信息
-u :默认不激活。若激活后,当使用未配置变量时,会显示错误信息;
-v :默认不激活。若激活后,在信息被输出前,会先显示信息的原始内容(未做变量解析);
-x :默认不激活。若激活后,在命令被运行前,会显示命令内容(做了变量解析,前面有 ++ 符号)
// 当前的终端配置
echo $-
// -v后,会显示执行的命令,但未做变量解析
/ # set -v && echo $HOME
/root
/ # set +v && echo $HOME
set +v && echo $HOME
/root
// set -x后,会显示解析的命令
/ # set -x && echo $HOME
+ echo /root
/root
/ # set +x && echo $HOME
+ set +x
/root
// set -u后,会有相关的提示信息
/ # set -u && echo $NOSET
/bin/sh: NOSET: parameter not set
/ # set +u && echo $NOSET
|
37. du - 忽略文件的统计
1
2
3
4
5
6
7
8
| // centos下的du
du -sh --exclude=./relative/path/to/uploads
du -ch --exclude={relative/path/to/uploads,other/path/to/exclude}
du -ch --exclude=relative/path/to/uploads --exclude other/path/to/exclude
// mac下,安装coreutils,然后利用
brew install coreutils
gdu -sh --exclude=./app/node_modules
|
38. pgrep,pkill - 基于进程名称查找、杀死进程
默认情况,可以通过grep+awk得到 pid,然后kill,
1
2
3
4
5
6
7
8
9
10
11
| sleep 100 &
// 查看指定名称进程相关信息,确定是否自己需要杀死的,以下几个都类似
ps -fp $(pgrep -d, sleep)
ps -jp $(pgrep -d, sleep)
ps -jlp $(pgrep -d, zsh)
// 杀死指定名称相关进程信息
$ pkill sleep
$ ps -fp $(pgrep -d, sleep)
[1] + 38024 terminated sleep 100
|
39. openssl 认证
1
2
3
4
5
| // 检测ioio.cool的TLS链接
openssl s_client -connect ioio.cool:443
// 检测证书内容
openssl x509 -text
...
|
40. tree 乱码问题
1
2
| # tree 当遇到一些文件名包含中文的文件,会默认按原样打印不可打印的字符而不是转义的八进制数字,可以加 `-N`参数规避
tree -N /tmp
|
41. locale、localectl - 本地化语言设置
41.1. localectl 命令操作
locale 被 glibc 和其它需要本地化的应用程序和库用来解析文本(或正确的显示当前区域的某些文字样式,如货币,时间,日期,特殊字符和其他的区域格式).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| // 列出所有启用的locale
$ locale -a
// 显示当前环境使用的locale
$ locale
// 系统配置所在,格式:[language][_TERRITORY][.CODESET][@modifier].
$ cat /etc/locale.conf
LANG="en_US.UTF-8"
// 另外,注意profile.d下的配置
$ ls /etc/profile.d/locale.sh
// 配置设定本地化和键盘布局
localectl status
localectl list-locales
localectl set-locale LANG=en_US.utf8
// 配置键盘布局,更多查看`man localectl`
localectl list-keymaps
localectl set-keymap MAP [TOGGLEMAP]
|
41.2. export 导出语言配置
1
2
3
4
5
| // 方法1,设定当前语言环境变量
$ export LANG="en_US.utf8"
// 方法2
$ LANG="en_US.utf8" ./my_application.sh
|
42. 磁盘分区+性能测试
42.1. 磁盘分区
分区分为主分区和扩展分区,主分区+扩展分区不能超过 4 个,另外扩展分区可以扩展多个逻辑分区,分区总数量不能超过 255
存储大小=柱面数 x 扇区大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // 查看
fdisk -l
// 磁盘分区(m是帮助信息,n创建新分区、p查看分区情况、w分区设置生效、-u以柱面数据展示,默认以扇区展示)
fdisk -u /development/vdb
p //打印当前分区表
n //创建扇区
p|e|l //主分区|扩展分区|逻辑分区
w //保存分区表(注意先利用p查看)
// 输入起始柱面,终止柱面(支持大小指定)
命令(输入 m 获取帮助):n
Partition type:
p primary (1 primary, 1 extended, 2 free)
l logical (numbered from 5)
Select (default p): l
添加逻辑分区 6
起始 柱面 (52021-83220,默认为 52021):
将使用默认值 52021
Last 柱面, +柱面 or +size{K,M,G} (52021-83220,默认为 83220):+10G
分区 6 已设置为 Linux 类型,大小设为 10 GiB
|
42.2. 磁盘文件格式化
1
2
3
| mkfs -t ext4 /development/vdb1
mkfs.ext4 /development/vdb5
mkfs.xfs /development/vdb6
|
42.3. 挂载到指定目录(需要先创建目录)
1
2
3
4
5
| // 设备标识|挂载点|文件类型|mount挂载方式|文件系统是否支持dump|启动是否做磁盘检测
UUID=87ba1103-a0d7-49ef-a8ae-6ce1d3fd2453 / ext4 defaults 1 1
/development/vdb1 /data ext4 defaults 0 0
/development/vdb5 /data/www ext4 defaults 0 0
/development/vdb6 /data/go xfs defaults 0 0
|
42.4. 查看挂载点和文件类型方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| [root@acp-test-001 ~]# lsblk -p // 查看挂载点和文件类型以及大小
// df查看
[root@acp-test-001 ~]# df -T
文件系统 类型 1K-块 已用 可用 已用% 挂载点
....
/development/vdb1 ext4 10190100 36896 9612532 1% /data
/development/vdb5 ext4 15350248 40984 14506452 1% /data/www
/development/vdb6 xfs 15714144 32992 15681152 1% /data/go
// 利用mount命令查看
[root@acp-test-001 ~]# mount|grep '^/development'
// 类型查看
[root@acp-test-001 ~]# fsck -N /development/vdb1
fsck,来自 util-linux 2.23.2
[/sbin/fsck.ext4 (1) -- /data] fsck.ext4 /development/vdb1
// 利用块ID查看
[root@acp-test-001 ~]# blkid /development/vdb5
/development/vdb5: UUID="bbbc2933-4d33-4490-8c03-25d847fe23a2" TYPE="ext4"
// 利用File命令查看
[root@acp-test-001 ~]# file -sL /development/vdb6
/development/vdb6: SGI XFS filesystem data (blksz 4096, inosz 512, v2 dirs)
// 查看配置
cat /etc/fstab
|
43. fio 磁盘性能测试
- -direct=1 表示测试时忽略 I/O 缓存,数据直写。
- -iodepth=128 表示使用 AIO 时,同时发出 I/O 数的上限为 128。
- -rw=randwrite 表示测试时的读写策略为随机写(random writes)。其它测试可以设置为:
- randread(随机读 random reads)
- read(顺序读 sequential reads)
- write(顺序写 sequential writes)
- randrw(混合随机读写 mixed random reads and writes)
- -ioengine=libaio 表示测试方式为 libaio(Linux AIO,异步 I/O)。应用程序使用 I/O 通常有两种方式:
- 同步:同步的 I/O 一次只能发出一个 I/O 请求,等待内核完成才返回。这样对于单个线程 iodepth 总是小于 1,但是可以透过多个线程并发执行来解决。通常会用 16−32 根线程同时工作将 iodepth 塞满。
- 异步:异步的 I/O 通常使用 libaio 这样的方式一次提交一批 I/O 请求,然后等待一批的完成,减少交互的次数,会更有效率。
- -bs=4k 表示单次 I/O 的块文件大小为 4KB。默认大小也是 4KB。
- 测试 IOPS 时,建议将 bs 设置为一个较小的值,如 4k。
- 测试吞吐量时,建议将 bs 设置为一个较大的值,如 1024k。
- -size=1G 表示测试文件大小为 1GiB。
- -numjobs=1 表示测试线程数为 1。
- -runtime=1000 表示测试时间为 1000 秒。如果未配置,则持续将前述-size 指定大小的文件,以每次-bs 值为分块大小写完。
- -group_reporting 表示测试结果里汇总每个进程的统计信息,而非以不同 job 汇总展示信息。
- -filename=iotest 指定测试文件的名称,例如 iotest。
- -name=Rand_Write_Testing 表示测试任务名称为 Rand_Write_Testing,可以随意设定。
1
2
3
4
5
6
7
8
9
| // 随机读写IOPS测试(小块操作)
fio -direct=1 -iodepth=128 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=iotest -name=Rand_Write_Testing
fio -direct=1 -iodepth=128 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=iotest -name=Rand_Read_Testing
// 顺序读写吞吐量测试(大块读写)
fio -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=1024k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=iotest -name=Write_PPS_Testing
fio -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=1024k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=iotest -name=Read_PPS_Testing
// 随机读写延时测试
fio -direct=1 -iodepth=1 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -group_reporting -filename=iotest -name=Rand_Write_Latency_Testing
fio -direct=1 -iodepth=1 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -group_reporting -filename=iotest -name=Rand_Read_Latency_Testingrandwrite
|
44. sshd
44.1. ssh 配置相关
客户端 ssh 连接参数配置,另外,我们也可以通过$ ssh -o StrictHostKeyChecking=no root@acp-test-02 方式指定。
1
2
3
4
5
6
7
8
| $ cat ~/.ssh/config
Host *
ServerAliveInterval 120
ServerAliveCountMax 3
Host github.com
Hostname github.com
User git
IdentityFile ~/.ssh/id_rsa_github
|
44.2. ssh 利用跳板机连接
1
2
| // 利用代理ServerA,连接ServerB,参考:https://wiki.gentoo.org/wiki/SSH_jump_host
ssh -J user01@ServerA:portA user02@ServerB -p portB -v
|
45. PS1 提示符设定
45.1. 新建 /etc/profile.d/ps1.sh
\u: Display the current username .\h: Display the hostname\W: Print the base of current working directory.\$: Display # (indicates root user) if the effective UID is 0, otherwise display a $.
1
2
3
4
5
6
7
8
9
10
11
12
13
| export PS1='\n\
[\[\e[32m\]\u\[\e[0m\]\
@\
\[\e[35m\]\h \
\[\e[36;1m\]\w\
\[\e[0m\]] \
$(RETVAL="$?"; echo -en "\e[33m{$(date +'%H:%M:%S')} ";
if [ "$RETVAL" -eq 0 ];then
echo -en "\[\e[32m\]($RETVAL)"
else
echo -en "\[\e[31;1m\a\]($RETVAL)"
fi)\n\
\[\e[0;1;34m\]\$ \[\e[0m\]'
|
45.2. 个性化登陆 Ascii Art 提示
对/etc/motd进行个性化设置:
1
2
3
4
5
6
7
8
9
| ----------------------------------------------------
_ _ _ _
/ \ _ __ ___| |__ ___| |_ __ _| |_
/ _ \ | '__/ __| '_ \/ __| __/ _` | __|
/ ___ \| | | (__| | | \__ \ || (_| | |_
/_/ \_\_| \___|_| |_|___/\__\__,_|\__|
Welcome to Alibaba Cloud Elastic Compute Service !
----------------------------------------------------
|