字符串可能看起来过于简单,但要好好使用它们,不仅需要了解它们的工作方式,还需要了解字节(byte),字符(character)和符文(rune)之间的区别,字符串(string)和字符串文字(string literal,也称字符串字面量)之间的区别,以及Unicode和UTF-8之间的区别,
常见一个问题:当我在位置n索引一个Go字符串时,为什么我不能得到第n个字符?
1. 什么是字符串
- 在Go中,字符串实际上是只读字节的片段([]byte)。
- 一个字符串包含任意字节,不需要关注保存Unicode、UTF-8文本或任何其他预定义格式。
- 一个字符串字面量(string literal),基于16进制编码(\xNN)表示法来定义一个包含一些特殊字节值的字符串常量:
| |
因为我们的示例字符串中的某些字节不是有效的ASCII,甚至不是有效的UTF-8,直接打印字符串会产生难看的输出。
2. 找到字符串的真正含义
2.1. 打印字符串
- 基于循环打印出来的字节,为杂乱字符串生成可显示输出的一种较短方法是使用fmt.Printf的
%x(十六进制)格式动词,它只是将字符串的连续字节转储为十六进制数字,每个字节两个。 - 一个很好的技巧是使用该格式的“space”标志,在%和x之间放置一个空格。
%q(带引号)动词将转义字符串中任何不可打印的字节序列,因此输出是明确的。%+q,同上,转义字符串中任何不可打印的字节序列,以正确格式化的UTF-8的Unicode值输出;
| |
我们仔细看,第3份输出,发现有两个ASCII符号:一个"=“符号(\x3d)和一个"空格”(\x20),以及一个"⌘"(\xe2\x8c\x98);因为“⌘”的Unicode编码为"U+2318",使用编码为UTF-8编码,基于16进制表示即e2 8c 98
tips: 在调试字符串的内容时,这些打印技术很有用,并且在随后的讨论中将会很方便。值得指出的是,对于字节切片,所有这些方法的行为与对字符串的行为完全相同。
2.2. 打印字节slice
- 基于单个字节打印,则看到的效果为常量中每个16进制对应的unicode的字符输出
- slice不能作为常量,定义一个sampleSlice变量后,有类似字符串的同等输出
| |
3. UTF8和字符串字面量(string literals)
- 由于字符串只是一堆字节,索引字符串会产生字节,而不是字符;这意味着当我们在字符串中存储字符值时,我们存储其字节的表示。
- 以下简单的程序,它以单个字符三种不同的方式打印字符串常量(一次作为普通字符串,一次作为ASCII引用的字符串,一次作为十六进制的单个字节)
为了避免混淆,我们创建一个“原始字符串”,用后引号括起来,因此它只能包含文字文本。(由双引号括起来的常规字符串可以包含我们在上面显示的转义序列)
| |
说明: ⌘字符,Unicode字符值U+2318,由字节e2 8c 98表示,并且那些字节是十六进制值2318的UTF-8编码;
如何创建字符串的UTF-8表示?简单的事实是:它是在编写源代码时创建的。即我们在code编辑器中,已经将⌘字符通过UTF-8编码好了,放入到源文件中,当我们打印出十六进制字节时,我们只是转储编辑器放在文件中的数据。
根据定义和构造,原始字符串将始终包含其内容的有效UTF-8表示。类似地,除非它包含像上一节那样的UTF-8中断转义符(%+q),否则常规字符串文字也将始终包含有效的UTF-8。
有些人认为Go字符串总是UTF-8,但它们不是(比如“\xbd\xb2=\xbc ⌘”),只有字符串字面量(string literals)是UTF-8(在存储时候已被编码)。
| |
4. code point、byte、character
到目前为止,我们一直非常小心地使用**“字节”和“字符”这两个词,这部分是因为字符串保存字节**,部分是因为“字符”的概念有点难以定义,Unicode标准使用术语**“代码点”**来表示由单个值表示的项目。
代码点U+2318,十六进制值为2318(十六进制表示\xe2\x8c\x98),代表符号⌘。
为了选择一个更平淡的例子,Unicode代码点U+0061是小写拉丁字母a, U+0300是重写字母à,通常字符可以由许多不同的代码点(code point)表示,由UTF-8字节表示。
计算中的字符概念因此含糊不清,或至少令人困惑,因此我们谨慎使用它。“代码点”有点拗口,所以Go为这个概念引入了一个较短的术语:符文(rune),该术语出现在库和源代码中,与“代码点”完全相同,只有一个有趣的补充。
Go语言将单词rune定义为int32类型的别名,因此当整数值表示代码点时,程序可以清除,而且,你可能会想到的一个字符常量在Go中称为符文常量。表达式的类型和值'⌘'是符号,整数值为0x2318。
5. 总结一下重点
- Go源代码总是UTF-8。
- 一个字符串包含任意字节。
- 字符串字面量文字(string literal),无字节级转义,则始终包含有效的UTF-8序列。
- Unicode代码点,在Go中称为符文rune。
- 在Go中,没有保证字符串中的字符被规范化。
6. 有关range loop
Go实际上只有一种方式特别是对待UTF-8,那就是在字符串上使用for range循环,会自动
- 对于范围循环(range loop),在每次迭代时解码一个UTF-8编码的符文值(rune值)。每次循环时,循环的索引是当前符文的起始位置,测量其字节,以码点(code point)为值;
- 另一种方便的Printf格式
%U的示例,它显示了代码点的Unicode值及其打印表示;
| |
7. 有关标准库
unicode/utf8:包含帮助程序来验证,反汇编和重新组装UTF-8字符串。这是一个等同于上面的范围示例的程序,但是使用该包中的DecodeRuneInString函数来完成工作。
| |
8. 小结
回答开头提出的问题:
- 字符串是从字节构建的,因此索引它们会产生字节,而不是字符。
- 字符串甚至可能不包含字符
- 事实上,“字符(character)”的定义是模糊的,试图通过由字符组成定义字符串来解决歧义是错误的。
- 尽管Go的字符串可能包含任意字节,但UTF-8是其设计的核心部分。
关于Unicode编码,UTF-8以及多语言文本处理,可以参阅:http://tkstorm.com/posts-list/programming/character-encoding/
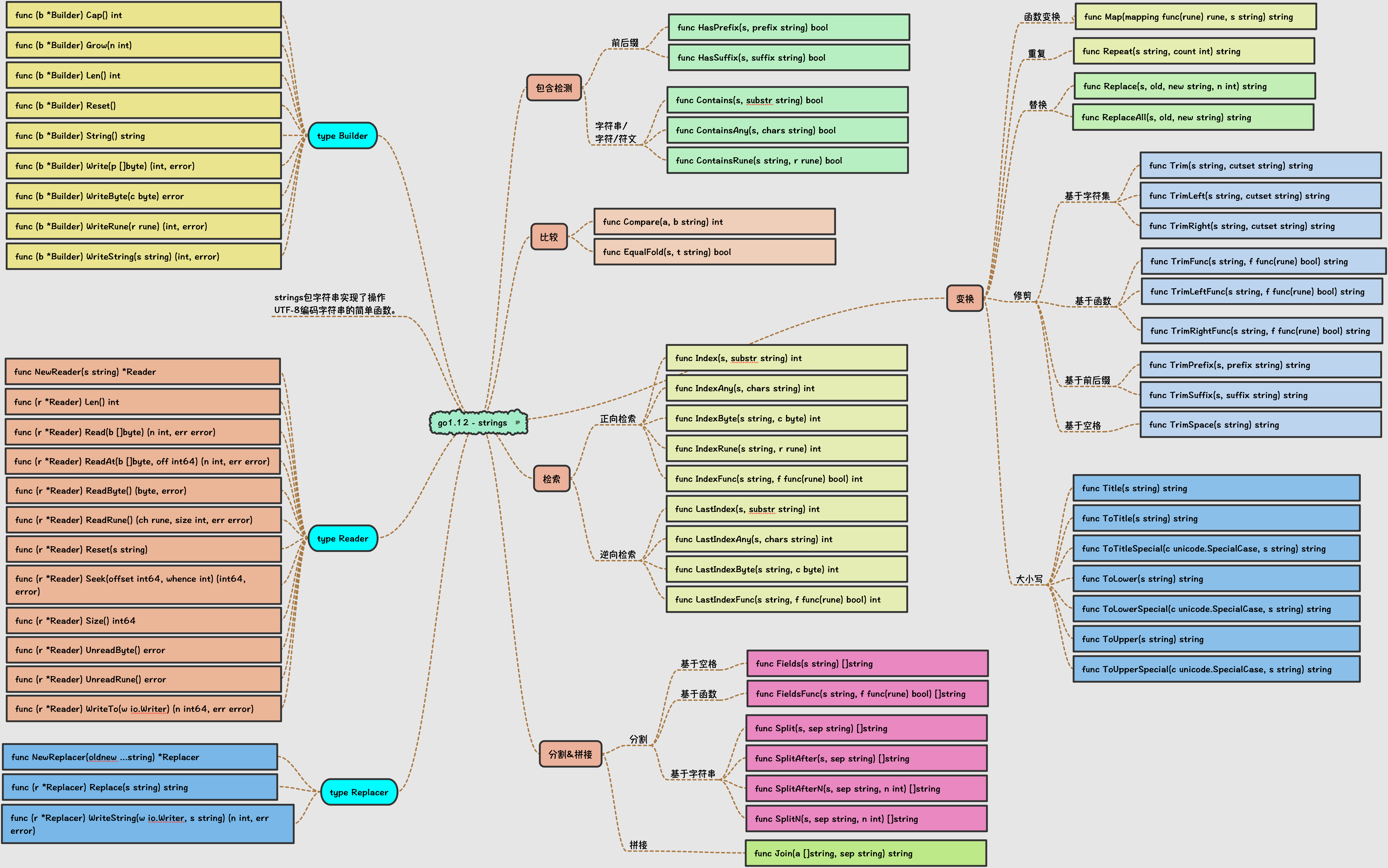
最后,补一张strings包的梳理图