MySQL支持多种类型的SQL数据类型:数字类型,日期和时间类型,字符串(字符和字节)类型,空间类型和JSON数据类型,简要介绍了Mysql的数据存储类型。
设计数据库时候,遵循的原则:在保证扩展性前提下,为了获得最佳存储空间,应该尝试在所有情况下使用最精确的类型。
1. 存储类型约定
1.1. 存储类型的基本定义举例
存储类型在声明时候,由几块组成:
| |
1.1.1. M - 最大显示宽度
- 整数类型:M表示最大显示宽度
- 浮点、定点类型:M是可以存储的总位数(精度)
- 字符串类型:M是最大长度
注意:允许的最大值M取决于数据类型。
从MySQL 8.0.17开始,对于整数数据类型,不推荐使用display width属性,并且将在以后的MySQL版本中删除它。
1.1.2. D - 适用于浮点和定点类型
- 浮点、定点类型:指示小数点后面的位数(刻度),最大可能值为30,但不应大于M-2。
1.1.3. fsp - 适用于TIME, DATETIME和 TIMESTAMP类型和表示小数精度秒
- 时间类型:小数部分秒的小数点后面的位数;
- 必须在1到6的值,为0表示没有小数部分范围为0;
1.1.4. 方括号([和])表示类型定义的可选部分
- UNSIGNED: 无符号数值类型
- ZEROFILL: 显示位宽不足时候,补零填充
- NULL: 允许为空
- NOT NULL: 不能为NULL值
- AUTO_INCREMENT: 自增
- …
1.2. 显示宽度示例
1.2.1. 定点精度
- 在保持精确精度很重要时使用这些类型,例如使用货币数据
- 标准SQL要求DECIMAL(6,2)能够存储六位数和两位小数的任何值,因此可以存储在salary 列中的值的范围-9999.99是 9999.99。
- 定点类型DECIMAL最大显示位宽为M=65;若D=0,则DECIMAL值不包含小数点或小数部分。
| |
以上,若针对decimal添加一行:
- 1234.56,存储OK
- 1234.567,存储OK,最后一位四舍五入,结果1234.57
- 12345.00,存储报错,超过最大精度(总位数)
- 12345,同上,一样超出最大精度报错,因为加两位小数点已经超过限制的精度了
1.2.2. 浮点类型
MySQL对于单精度值使用四个字节,对于双精度值使用八个字节存储。
| |
以上,若针对float列添加一行:
- 1234.567,存储OK,最后一位四舍五入,结果1234.57
- 12345.00,存储报错,超过最大精度(总位数)
- 12345,同上,一样超出最大精度报错,因为加两位小数点已经超过限制的精度了
2. Mysql数据存储类型
2.1. 存储类型包含
- 数值类型:整型、浮点型、bool类型
- 字符串类型:char、varchar、text、emun枚举类型、SET集合类型等
- 时间类型:timestamp、datetime、date等
- 空间类型:GEO地理位置等
- JSON类型
2.2. 数值类型
- BIT[(M)] : M从1~64
- TINYINT[(M)][UNSIGNED] [ZEROFILL],BOOL,BOOLEAN
- SMALLINT[(M)][UNSIGNED] [ZEROFILL]
- MEDIUMINT[(M)] [UNSIGNED] [ZEROFILL]
- INT[(M)] [UNSIGNED] [ZEROFILL],INTEGER[(M)] [UNSIGNED] [ZEROFILL]
- BIGINT[(M)] [UNSIGNED] [ZEROFILL]:M不应使用大于(63位)的无符号大整,通过使用字符串存储它
- SERIAL:BIGINT UNSIGNED NOT NULL AUTO_INCREMENT UNIQUE 的别名
- DECIMAL[(M[,D])] [UNSIGNED] [ZEROFILL],同DEC[(M[,D])] [UNSIGNED] [ZEROFILL], NUMERIC[(M[,D])] [UNSIGNED] [ZEROFILL]FIXED[(M[,D])] [UNSIGNED] [ZEROFILL]
- FLOAT[(M,D)] [UNSIGNED] [ZEROFILL],同DOUBLE PRECISION[(M,D)] [UNSIGNED] [ZEROFILL], REAL[(M,D)] [UNSIGNED] [ZEROFILL]
- DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
2.2.1. 数值类型所需的存储空间以及值可表示的范围
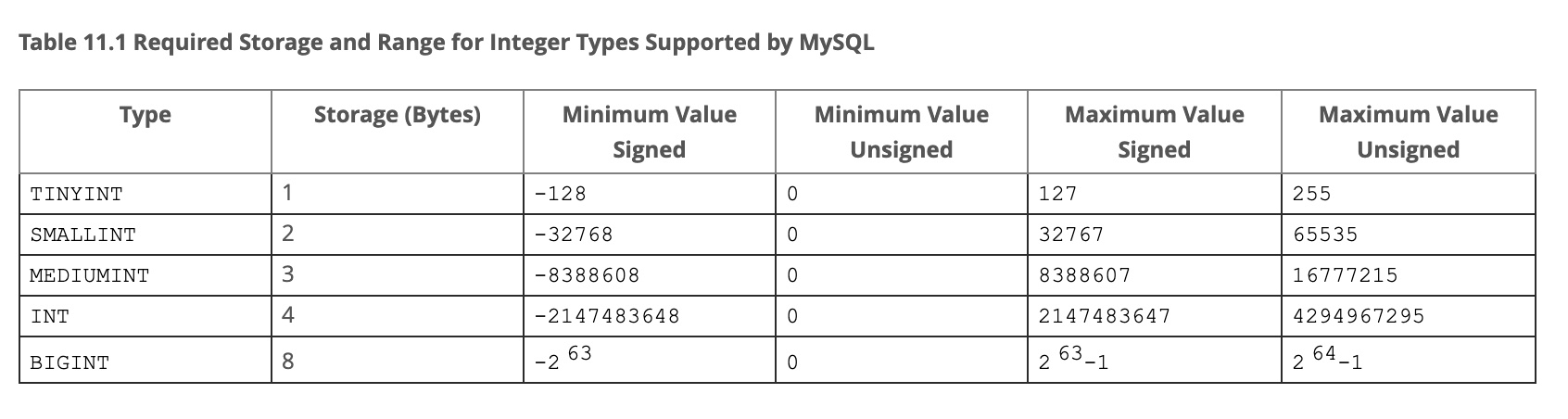
2.2.2. 数值存储相关
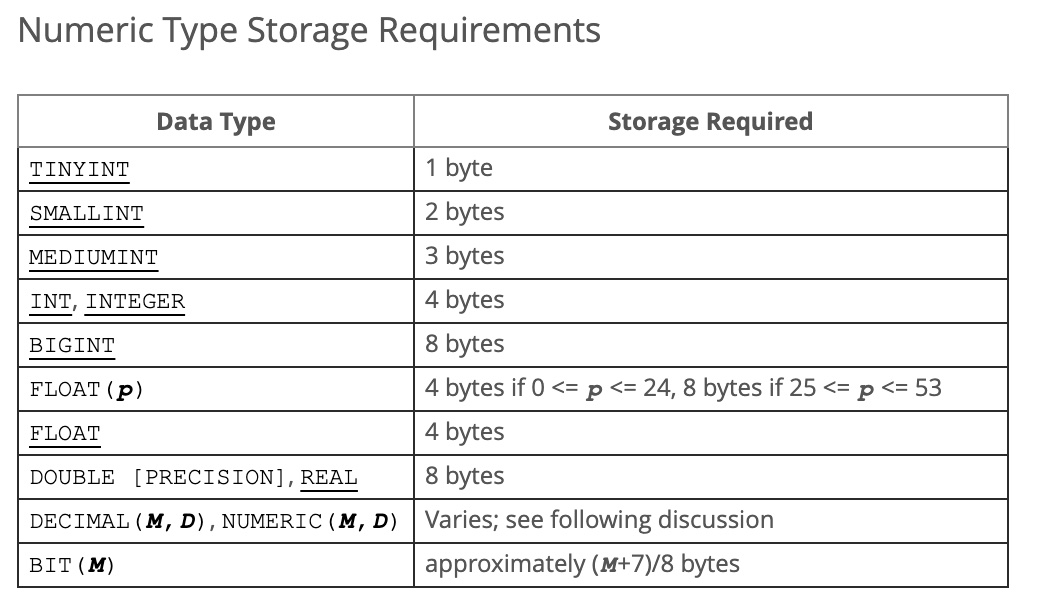
2.3. 时间类型
DATETIME或TIMESTAMP 值可以包括高达微秒(6位)精度的尾随小数秒部分,同时TIMESTAMP存储的值,与time_zone时间有关系!
- TIME:-838:59:59 ~ 838:59:59,不单单是天,也可以是两个事件发生的时间间隔时间;
- YEAR:1901
2155, 169(20012069),7099(1970~1999),NOW()函数 - DATE:具有日期部分但没有时间部分的值,以’YYYY-MM-DD’格式检索和显示,‘1000-01-01’到 ‘9999-12-31’
- DATETIME:包含日期和时间部分的值,以’YYYY-MM-DD hh:mm:ss’格式检索和显示, ‘1000-01-01 00:00:00’到'9999-12-31 23:59:59’。
- TIMESTAMP:包含日期和时间部分的值,具有'1970-01-01 00:00:01’UTC到'2038-01-19 03:14:07’UTC 的范围,可以支持精度。
不同时间类型转换问题,存在时间的丢失:https://dev.mysql.com/doc/refman/8.0/en/date-and-time-type-conversion.html
2.4. 字符串类型
- char
- varchar
- binary、varbinary
- blob、text
- enum
- set
2.4.1. 字符集对存储的影响
为了计算用于存储特定的字节数 CHAR, VARCHAR或 TEXT列的值时,必须考虑到用于该列是否值包含多字节字符的字符集。
特别是,在使用utf8 Unicode字符集时,必须记住并非所有字符都使用相同的字节数。utf8mb3和utf8mb4 字符集每个字符最多可分别需要三个和四个字节。
VARCHAR, VARBINARY以及 BLOB和 TEXT类型是可变长度类型的。对于每个,存储要求取决于以下因素:
- 列值的实际长度(L)
- 列的最大可能长度(M)
- 用于该列的字符集,因为某些字符集包含多字节字符(比如utf8mb4,Maxlen为4)
| |
另外,特定的字符集未包含的字符,是无法被写入的,比如若使用了ascii字符集,定义了一列char(10),是存储不了字符中
2.4.2. 字符串类型存储限制
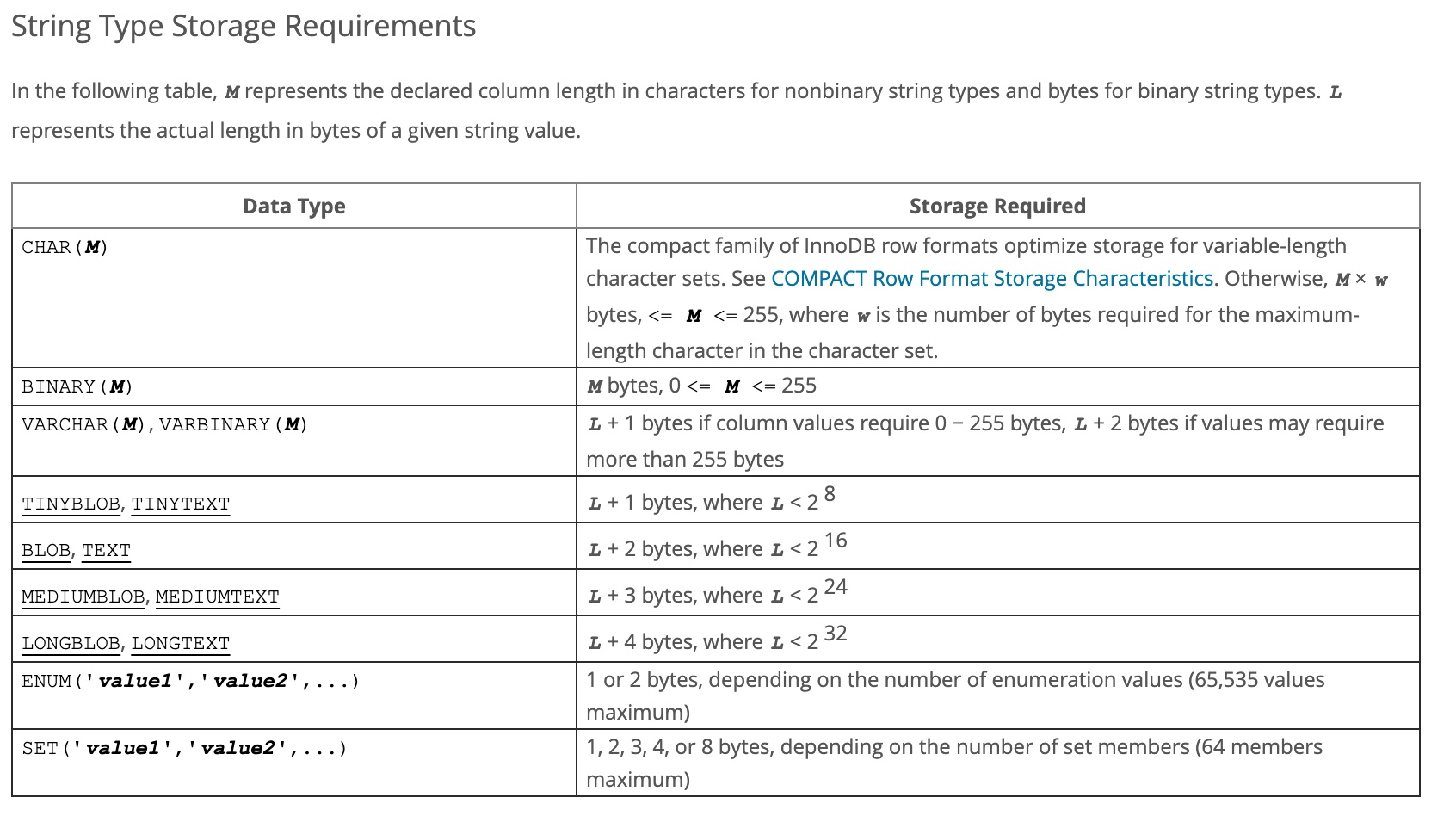
- CHAR(M):紧凑的InnoDB行格式系列优化了可变长度字符集的存储。M × w (M为显示位宽,latin1和ucs2双字节字符集的’a’都代表M中的1个基础长度,w为字符串中字符集最大字节数)
- VARCHAR(M):
- 若存储内容在0~255个字节,则存储大小为
L+1个字节; - 若存储内容超过255个字节,则为
L+2个字节;
- 若存储内容在0~255个字节,则存储大小为
- TEXT:
- TINYTEXT:存储占用
L+1个字节,最大存储L < 2^8 - TEXT: 存储占用
L+2个字节,最大存储L < 2^16 - MEDIUMTEXT:存储占用
L+3个字节,最大存储L < 2^24 - LONGTEXT:存储占用
L+4个字节,
- TINYTEXT:存储占用
2.4.3. varchar存储示例说明
VARCHAR(255)列,可以包含最大长度为255个字符的字符串,在latin1字符集和ucs2字符集对于字符串 ‘abcd’存储的差异:
- 使用latin1字符集(每个字符一个字节),所需的实际存储量是string(L)的长度,加上一个字节来记录字符串的长度。(L为4,存储要求为5个字节)
- 如果声明同一列使用ucs2双字节字符集(4个字符,在ucs2下每个字符占2个字节,则L为8字节;同时申明了varchar(255)显示位宽为255,在ucs2下,存储字节需要255*2=510字节,超过了255,因此需要多加2个字节,
L+2=8+2=10字节,因此存储要求为10个字节)
因为utf8mb4采用变长编码,在存储拉丁文时候与存储汉字时候的存储所占用的字节是有差异的!!
如果varchar全部存储4字节的字符,则使用该字符集的列可以声明为最多16,383(65535/4)个字符。
2.4.4. CHAR和VARCHAR值所需的存储空间
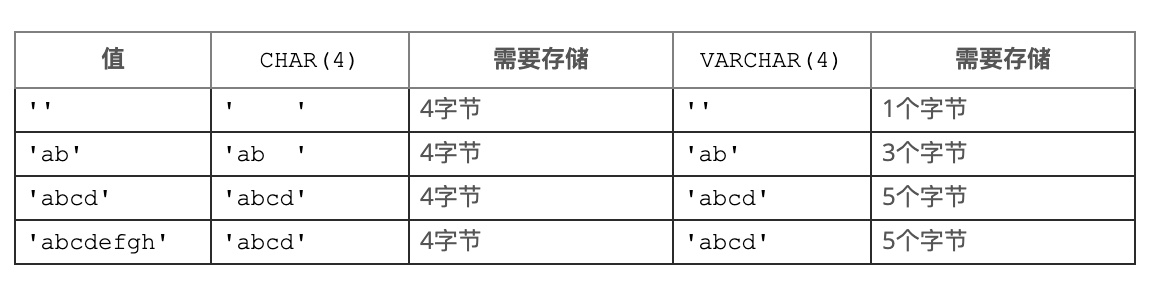
2.4.5. ENUM类型
ENUM是一个字符串对象,其值从允许值列表中选择,其优势:
- 在列具有有限的可能值集的情况下的紧凑数据存储。(100万行,某列都是ENUM类型的’x-small’,存储是100万字节,而非700万字节)
- 可读的查询和输出,数字将转换回查询结果中的相应字符串。
ENUM注意:
- 枚举不是数字类型
- 排序问题,ENUM值根据其索引号进行排序,这取决于列规范中列出枚举成员的顺序,因此,通过以下方式之一确保排序正确:
- ENUM枚举值已按字母顺序指定列表
- 基于词法排序,比如:
ORDER BY CONCAT(col)
- 查询支持序号查询,索引从1开始,见示例
- ENUM创建表时,会自动从表定义中的成员值中删除尾随空格
- 强烈建议不要不使用数字作为枚举值,因为容易混淆(
numbers ENUM('0','1','2'),对应数值索引值 1,2以及3) - 空值问题:严格模式下插入无效ENUM值会直接报错,可以支持0值插入(索引0代表空值);
存储方面,ENUM占用1或2个字节,具体取决于枚举值的数量(最多65,535个值)
2.4.6. ENUM示例
| |
2.4.7. SET类型
SET是一个字符串对象,可以包含零个或多个值,每个值都必须从创建表时指定的允许值列表中选择。
SET由多个集成员组成的列值由用逗号(,)分隔的成员指定,这样做的结果是SET成员值本身不应包含逗号。(业务场景如用户特性记录,可以基于SET集合来收集)
注意:
- 如果启用了严格的SQL模式,则尝试插入无效SET值会导致错误。
- 查询多个SET关系,需要涉及多次find_in_set(‘val’, column)
| |
3. 选择正确的存储类型
原则:在保证可预见的扩展性前提下,为了获得最佳存储空间,应该尝试在所有情况下使用最精确的类型。
例如,如果使用一个整数列值的范围从1到 99999,MEDIUMINT UNSIGNED是最好的类型。在表示所有必需值的类型中,此类型使用最少的存储量。
- 如果准确性不是太重要或者速度是最高优先级,那么DOUBLE类型可能足够好。
- 对应精度很重要,可以使用decimal定点类型(精确的行为是特定于操作系统的,但通常效果是截断到允许的位数。)
- 对于高精度,始终可以转换为存储在中的定点类型BIGINT,这使您可以使用64位整数进行所有计算,然后根据需要将结果转换回浮点值。(比如银行利息来说,需要保留小数点后8位)
有个地理空间位置以及JSON类型后续在Nosql中同步说明!
4. 参考
- 类型存储要求:https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html
- numeric-type-overview: https://dev.mysql.com/doc/refman/8.0/en/numeric-type-overview.html