1. 系统监控解决方案
- 基于CollectD,InfluxDB和Grafana实现(CollectD是基于C语言写的,基于模块化,组件很丰富)
- 基于Prometheus和Grafana实现 (主要基于这套)
2. 基于Prometheus和Grafana实现
2.1. 先附一张效果图

3. collectd vs Telegraf vs Prometheus:有什么区别?
对比参见:https://stackshare.io/stackups/collectd-vs-prometheus
3.1. Collectd
系统和应用程序度量收集器,collectd收集有关其运行的系统的统计信息并存储此信息,然后使用这些统计数据来查找当前的性能瓶颈(即性能分析)并预测未来的系统负载(即容量规划)。
特定:收集帮助分析
3.2. Telegraf
Telegraf是收集,处理,汇总和编写指标的代理。设计目标是通过插件系统实现最小的内存占用,以便社区中的开发人员可以轻松添加对收集指标的支持
3.3. Prometheus
整体Prometheus架构:
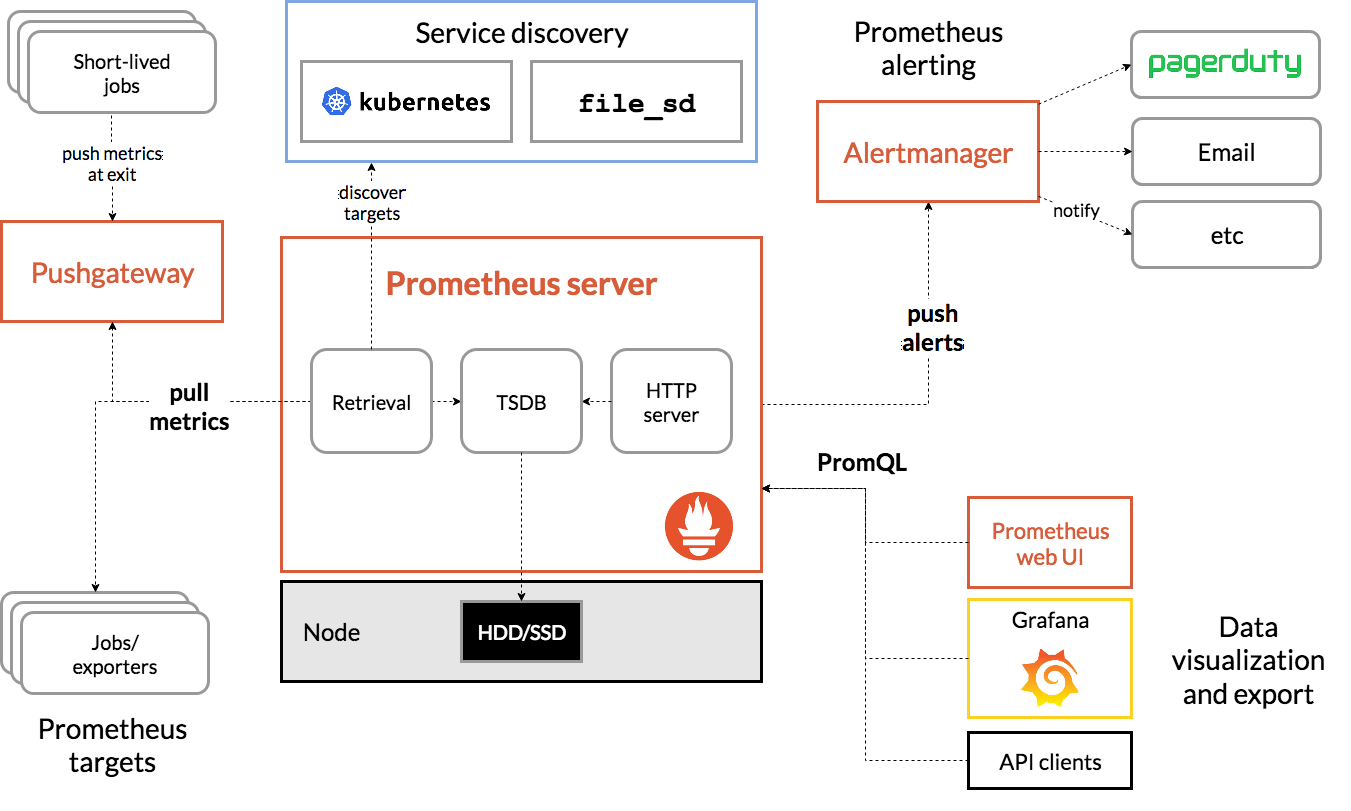
由SoundCloud基于Golang开发的开源服务监控系统和时间序列数据库。
Prometheus是一个系统和服务监控系统,它以给定的时间间隔从配置的目标收集指标,评估规则表达式,显示结果,并且如果观察到某些条件为真,则可以触发警报。
普罗米修斯的主要特点是:
- 具有由度量名称和键/值对标识的时间序列数据的多维数据模型
- PromQL,一种灵活的查询语言, 可以利用这一维度
- 不依赖分布式存储; 单个服务器节点是自治的
- 时间序列集合通过HTTP上的拉模型发生
- 推送时间序列通过中间网关支持
- 通过服务发现或静态配置发现目标
- UI较弱,可与与Grafana结合使用
普罗米修斯的组件,Prometheus生态系统由多个组件组成,其中许多组件是可选的:
- 主要的Prometheus服务器,用于存储时间序列数据
- 用于检测应用程序代码的客户端库
- 用于支持短期工作的推送网关
- 针对HAProxy,StatsD,Graphite等服务的专用出口商
- 一个alertmanager处理警报
- 各种支持工具
4. 其他相关性软件简要概述
- InfluxDB:开源的分布式时间序列数据库,没有外部依赖关系
- Zabbix: 跟踪,记录,提醒和可视化IT资源的性能和可用性
- Kabana: ELK技术栈,探索和可视化您的数据
- Prometheus:基于Golang开发的告警、事件监控的应用软件。Prometheus支持一些监控和管理协议,以实现转换的互操作性:Graphite,StatsD,SNMP,JMX和CollectD。
- Grafana:Grafana是一个通用仪表板和图形编辑器。它专注于提供丰富的时间序列度量可视化方法,主要是通过图形,但支持通过可插拔面板架构可视化数据的其他方法。它目前对Graphite,InfluxDB和OpenTSDB提供了丰富的支持。但是通过插件支持其他数据源。
- StatsD:Node.js平台上运行,并侦听通过UDP发送的统计信息,如计数器和计时器,并将聚合发送到一个或多个可插入后端服务(例如,Graphite)。
- Nagios:用C语言编写并在GNU通用公共许可证下发布的主机/服务/网络监控程序,完整的服务器,交换机,应用程序和服务监控和警报
- Ganglia:可扩展的分布式监控系统,适用于集群和网格等高性能计算系统
- Fluentd:Fluentd从各种数据源收集事件并将其写入文件,RDBMS,NoSQL,IaaS,SaaS,Hadoop等。Fluentd可帮助您统一日志记录基础架构。
- Jaeger: Uber作为开源发布的分布式跟踪系统
- collectd: 系统和应用程序指标收集器
5. PG对服务器资源节点监控的落地
实现监控单台Server的磁盘、网络、内存、CPU等指标的监控
5.1. 实施流程
- 下载并安装Prometheus,部署在监控服务器上
- 下载并安装Node_Exporter,部署在被监控节点服务器
- 下载并安装Grafana,部署在监控服务器上
- 基于Nginx作为反向代理,配置Grafana、Prometheus
- 配置Grafana,基于PromQL实现节点的磁盘、网络、内存、CPU情况监测
5.2. 下载安装Prometheus、Node_Exporter、Grafana
- https://github.com/prometheus/prometheus
- https://github.com/grafana/grafana
- https://github.com/prometheus/node_exporter
5.3. 配置Node Exporter服务
以下在被监控节点服务器上部署,提供一个http的api接口给到Prometheus来Pull 指标数据,暴露的节点在:9100上面提供web api服务;
注意:--no-collector.netstat,是因为node-exporter在收集netstat时候报错,是一个官方Bug,暂时先忽略收集!
| |
5.4. Nginx - 认证文件生成
考虑到Nginx的aut_basic,先简单安装htpasswd和设置好用户名、密码,基本认证密码可以基于htpasswd工具生成
| |
5.5. Nginx - 配置Nginx反向代理
ssl_cert.conf配置,基于acme.sh安装的ssl证书配置auth_basic,- 针对Grafana不用开启简单认证,因为Grafana自己有一套认证方式,可以参考Grafana文档的认证文档;
- 针对Prometheus开启简单认证,作为Grafana的数据源
prometheus.conf vhos部分:
| |
ssl证书部分
| |
5.6. 启动Prometheus服务
配置prometheus.yml,新增node job,定期去被监控节点服务器上去Pull内容(这里是去上面node_exporter暴露API节点上去PULL数据)
| |
5.7. 启动Grafana服务
Grafana配置在安装目录下的conf内(我这里是基于源码包下载安装的,非rpm):
| |
遗留问题,Promethues和Grafnana的systemd服务没有配置
5.8. Grafana - 配置
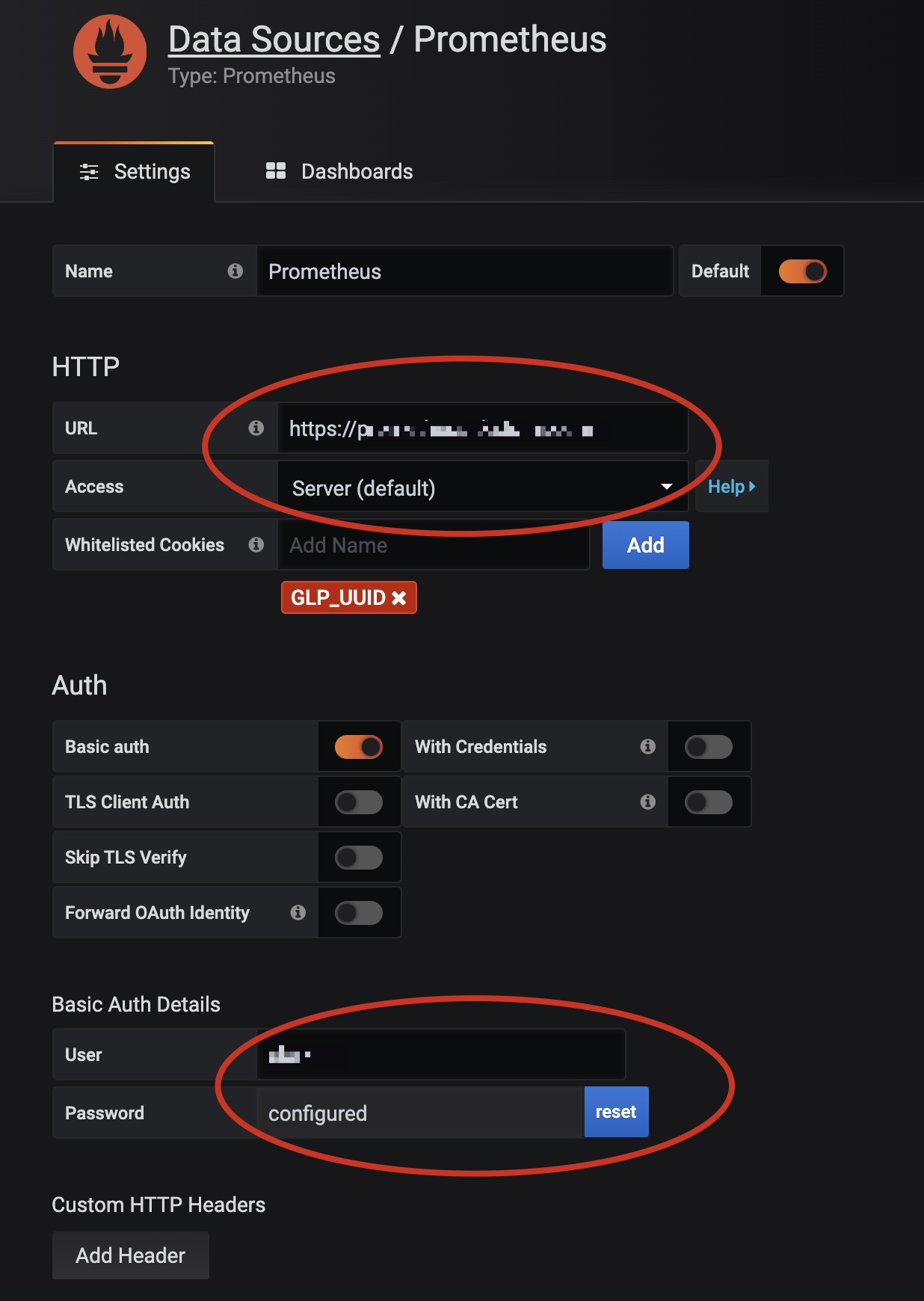
- 配置数据源,选择Prometheus数据源,注意URL、Basic auth两处地方:
5.9. Metric Type
理解Metric types,以prometheus job的/metric指标监控为例说明:
| |
指标由指标名(这里是prometheus_http_requests_total)、花括号里的labels(比如code、handler)以及label values(比如200、302等)组成。其中labels可以理解为维度,PromQL提供查询指标按时间、维度聚合,参见下面的示例。1
5.10. PromQL配置
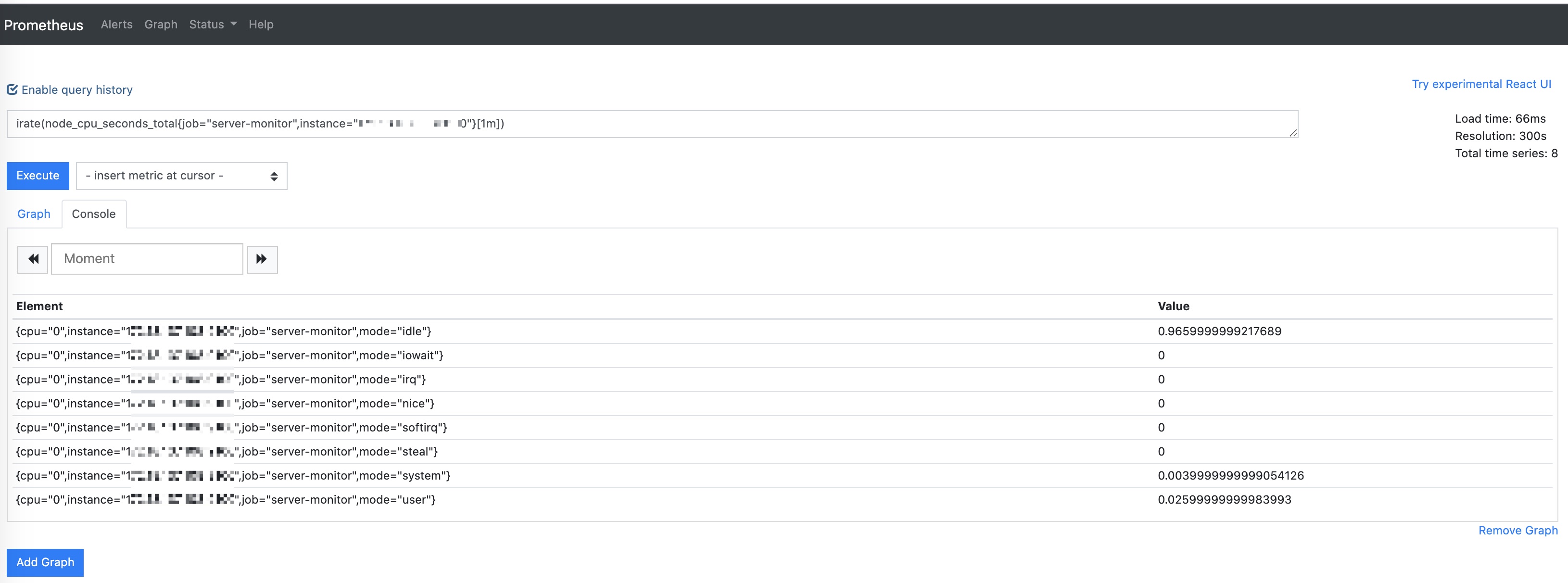
通过Create一个一个的新建面板,就可以实现基础设施的监控,这里简要配置几个PromQL。
Tips: 可以通过查看prometheus的
/graph的console查看指标名支持的labels情况,以及相关的查询语句的的值
| |
Console查看:
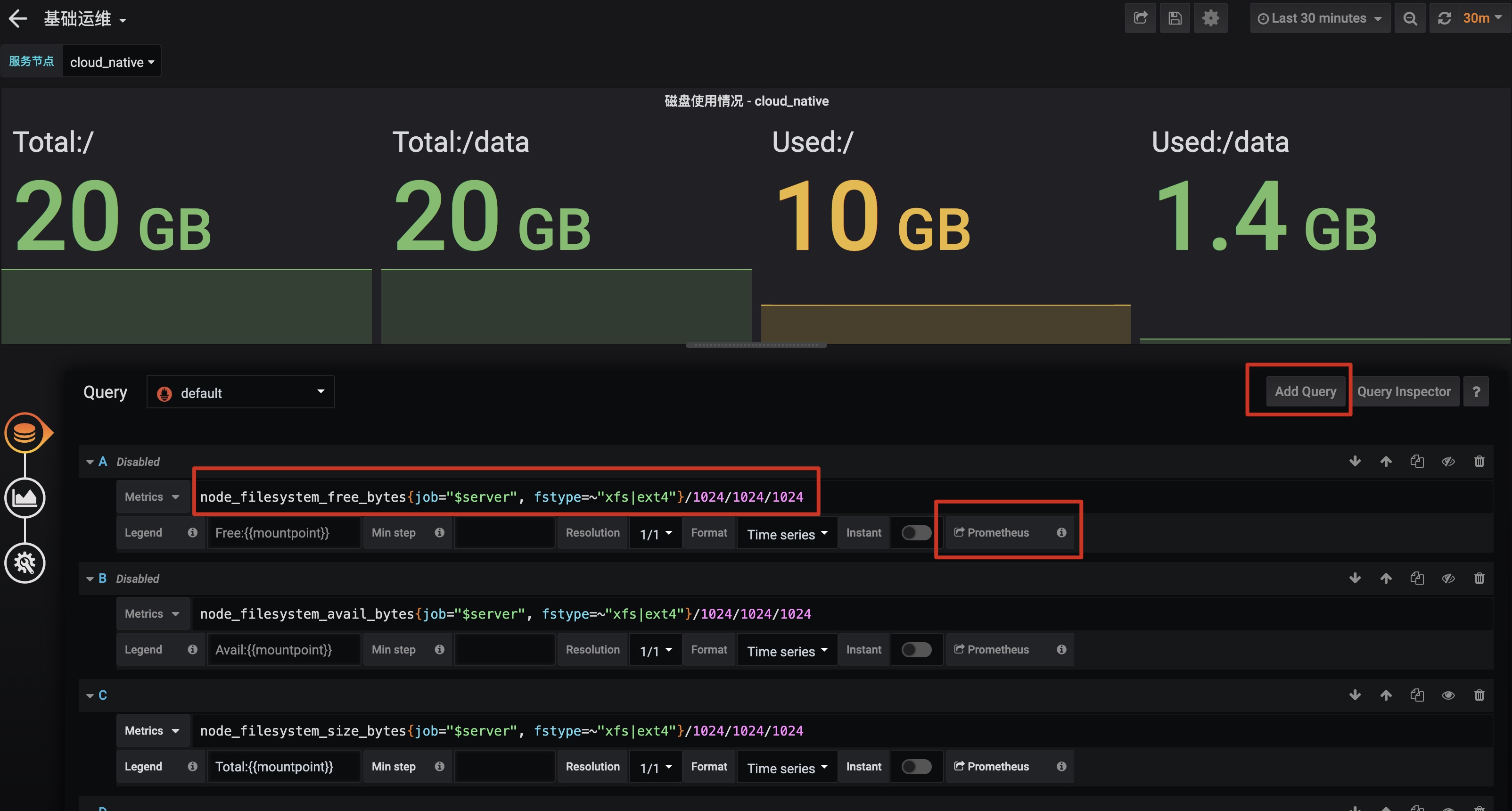
5.11. 拿节点上下文切作为示例配置
通过选择合适的数据源,在PromQL区域增加对应的监控项内容;利用AddQuery添加额外的监控项:
5.12. 模板变量参考 2
可以在变量中使用变量,而不必在指标查询中对服务器,应用程序和传感器名称等进行硬编码。变量在仪表板顶部显示为下拉选择框。这些下拉菜单使您可以轻松更改仪表板上显示的数据。
如果在Grafana中的查询变量指定,Query类型允许查询Prometheus获取metrics, labels,label values内容:
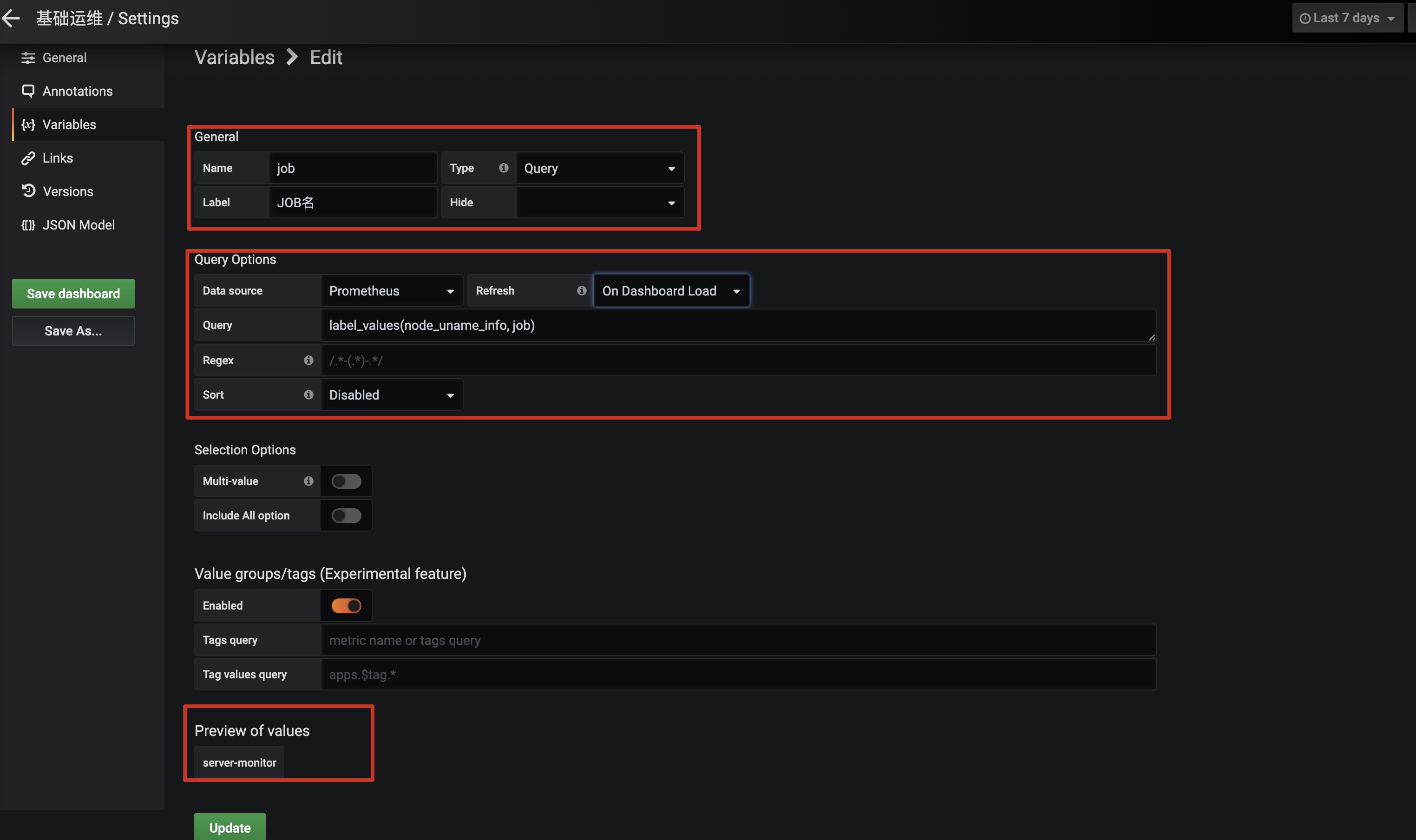
label_names():获取所有标签名label_values(label):基于标签名获取所有值label_values(metric, label):获取指定指标下的标签值,比如label_values(node_uname_info, job)获取joblabel_values(node_uname_info, nodename)获取节点主机名label_values(node_uname_info, instance)获取IP实例
metrics(metric):获取匹配指定正则标签的所有,比如metrics(.*)先查看所有指标query_result(query):返回promQL查询结果
考虑到多节点的监控,我们需要将不同的Server标识(如实例IP、Job名称等)做成通用变量,这样在Grafana大盘上面,可以简单的通过参数就可以指定!
以上基本摸清后,可以从Grafana上面参照其他人分享出来的配置,导入自己环境进行相关调试,做到适配自己的基础运维环境
配置列表:
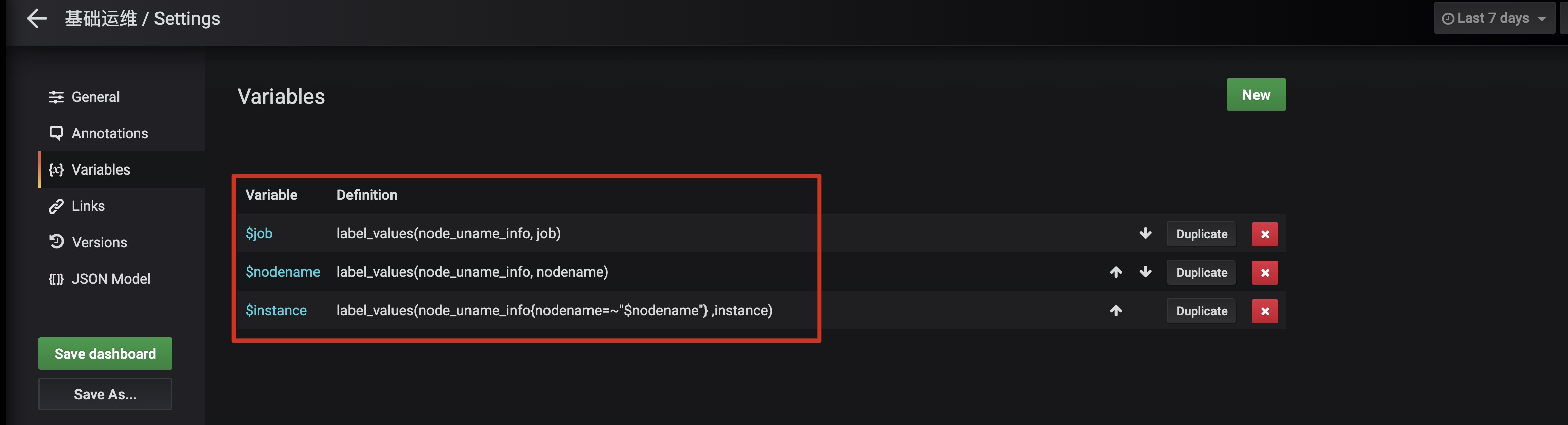
配置明细:
6. 小结
简要介绍了基于prometheus+grafana对系统资源节点监控解决方案,grafana弥补了prometheus的UI短板,同时prometheus定期从指定的job抓取相关的指标存储在自己时序数据库中。
我们可以通过prometheus的web界面/metric、graph、console等界面查看和调试指标,在grafana设置好prometheus数据源后,可以通过PromQL查询语句,统计相关指标的资源使用情况,结合grafana的变量功能,能够做到美观和适用的节点资源监控效果。
如果要达到生产级别的使用,grafana变量维度的丰富,prometheus时序数据库的高可用、高并发以及扩容支持,以及监控告警都是是需要重点考虑的。
7. 链接参考
- Prometheus介绍:https://en.wikipedia.org/wiki/Prometheus_(software)
- Prometheus Document: https://prometheus.io/docs/introduction/overview/
- 与prometheus相关性软件:https://stackshare.io/prometheus/alternatives
- Prometheus的PromQL语法:https://prometheus.io/docs/prometheus/latest/querying/examples/
- Grafana变量参考:https://grafana.com/docs/grafana/latest/reference/templating/