1. 系统性能监控思路
1.1. 好的监控系统
全面的、可量化指标:
- 系统监控需要涵盖整体资源使用情况:CPU、内存、磁盘IO、文件系统、网络等各种资源
- 应用性能监控需要包括进程CPU、磁盘IO、内存外,更需要包括接口调用耗时(响应时间)、接口错误数、请求日志上下文等
1.2. USE法 (使用率-Utilization 饱和度-Saturation and 错误数-Error)
- 使用率:资源的时间或容量百分比,比如80%磁盘容量被使用
- 饱和度:资源繁忙程度,与等待队列相关,100%饱和度表示无法接受更多的请求
- 错误数:表示错误的时间个数,错误越多表明系统的问题越严重
对CPU、内存、磁盘、文件系统、网络等硬件资源,以及对文件描述符、连接数、连接跟踪数等软件资源,USE都可以帮你快速定位出那种资源问题
1.3. 配合USE法的监控系统
- 收集、存储、可视、告警、分析
- 开源产品:
Zabbix、Nagios、Prometheus
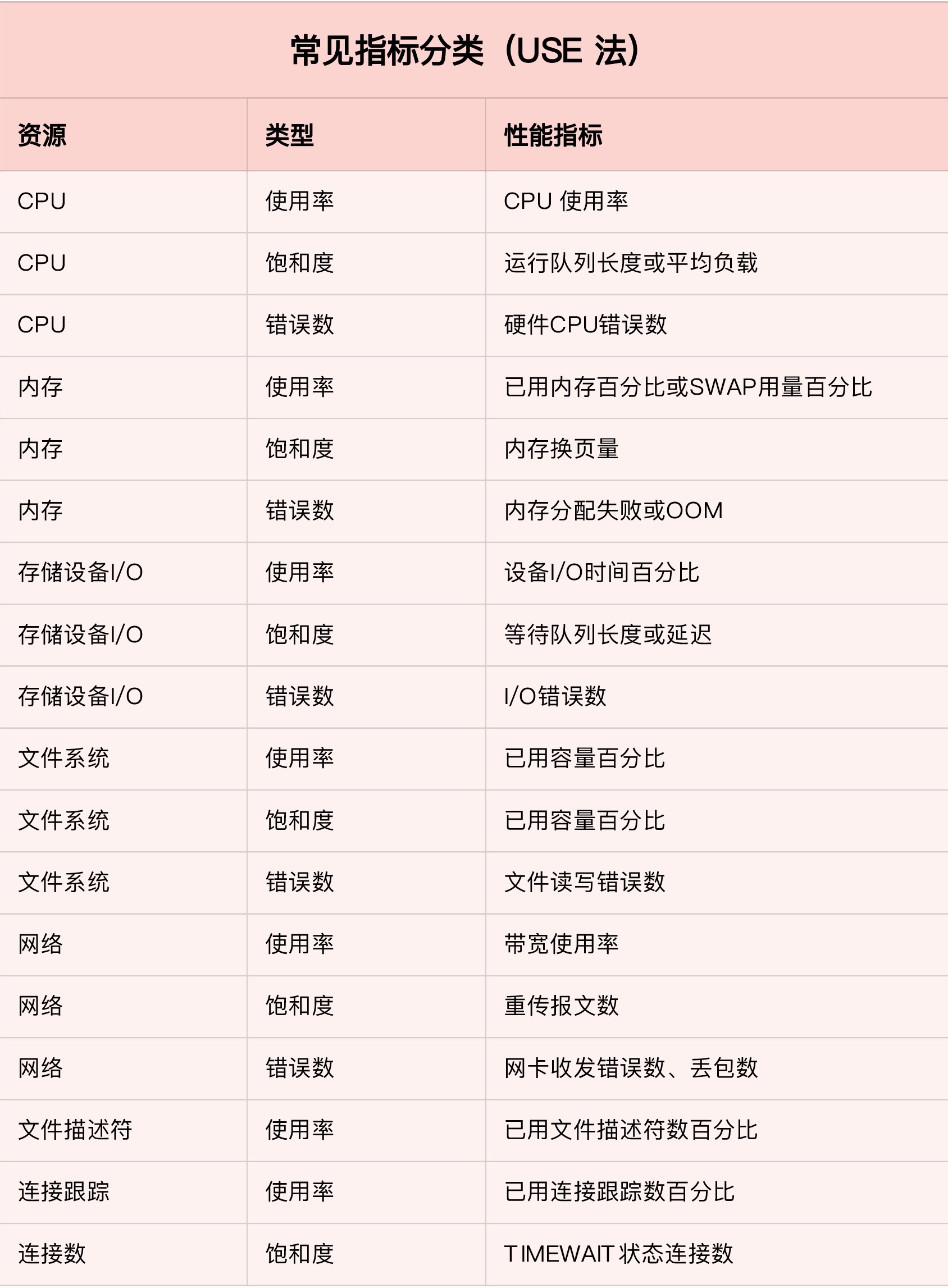
1.4. Prometheus
- 采集模块
- Targets:采集的对象
- Retrieval:采集工具(Pull方式:采集目标提供HTTP,采集Push方式: 采集目标主动推到GW)
- 支持服务发现,k8s平台有效
- 数据存储模块
- TSDB(Time Series Database 时序数据库),时间为索引、数据量大、追加写方式写入,代表是InfluxDB
- 数据查询和处理模块
- PromQL,提供数据查询和基本数据处理,提供过滤语法,告警系统和可视化(Grafana的基础)
- 告警模块
- AlterManager,基于PromQL语言的触发条件、告警规则配置管理以及告警发送
- 可视化展示模块
- 配合Grafana,可以构建非常强大的图形界面
2. 应用性能监控思路 - (指标监控+日志监控)
2.1. RED法(请求频率-Rate 请求错误-Error 请求耗时-Duration)
基于请求数、响应耗时、请求错误这三个黄金指标,可以定位性能接口,但具体应用服务的“性能瓶颈区”还是不清楚
2.2. 性能瓶颈区 - 全链路跟踪
- 应用进程的资源使用情况,进程占用的CPU、内存、磁盘IO、网络等;
- 应用程序之间的调用情况,调用频次、错误数、响应时间,应用程序不是孤立的,存在服务依赖;
- 应用程序内部对基础服务的调用请求情况,包括调用频次、错误数、延时时间等;
- 应用程序内部核心逻辑运行情况;
分析一个请求处理的调用链,到底哪个组件或者服务是导致性能问题的罪魁祸首;有了应用程序内部核心逻辑的运行情况,就可以定位到具体的处理环节导致的性能问题;
可以将这些指标,再纳入到监控系统,比如(prometheus+grafana)中,就可以和系统监控一样,通过监控和告警将应用程序性能也直观展示出来;
除此之外,由于业务系统会涉及到一连串的多个服务,形成了一个复杂的分布式调用链,为了迅速定位这类跨应用的性能瓶颈,可以采用诸如Zipkin、Jaeger、Pinpoint等开源的全链路跟踪工具;
全链路还可以生成调用拓扑图,在分析复杂系时候尤其有用;
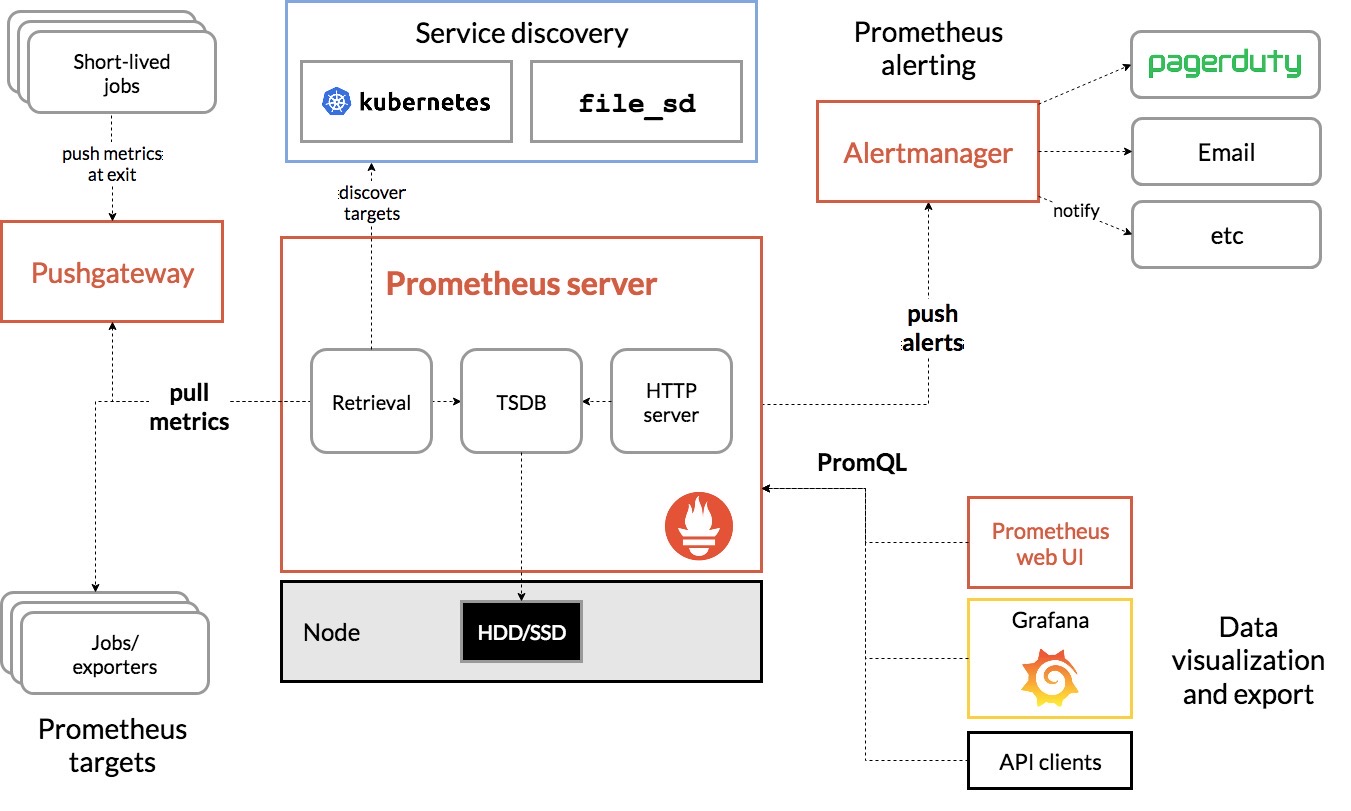
2.3. 日志监控
只有指标的话还不够,同样一个接口,不同的入参有不同的问题,日志就是这些上下文的最佳来源;
- 指标:是特定时间段的数值型测量数据,通常以实际序列的方式处理,适合实时监控;
- 日志:日志是某个时间的字符串消息,配合搜索引擎进行索引后,才能进行查询和汇总分析,可以采用经典的
ELK技术栈,Logstash性能损耗大的话,通过Fluentd替代,即EFK技术栈
3. 分析定位性能问题的一般步骤
在收到告警,发现了系统或应用性能后,如何进一步分析它的根源?
系统资源和应用程序本来就是相辅相成、互相影响的一个整体,应用程序内存泄露,会导致系统内存不足;过多的IO请求,拖慢整个系统的IO请求,大多数情况下,资源瓶颈和应用瓶颈都是同一个问题导致,并不需要重复分析;
3.1. 系统资源瓶颈分析步骤
- CPU性能分析:top、vmstat、pidstat、strace、perf
- 内存性能分析:free、vmstat、sar、pidstat
- 磁盘文件系统IO性能分析:iostat、sar、pidstat、vmstat…
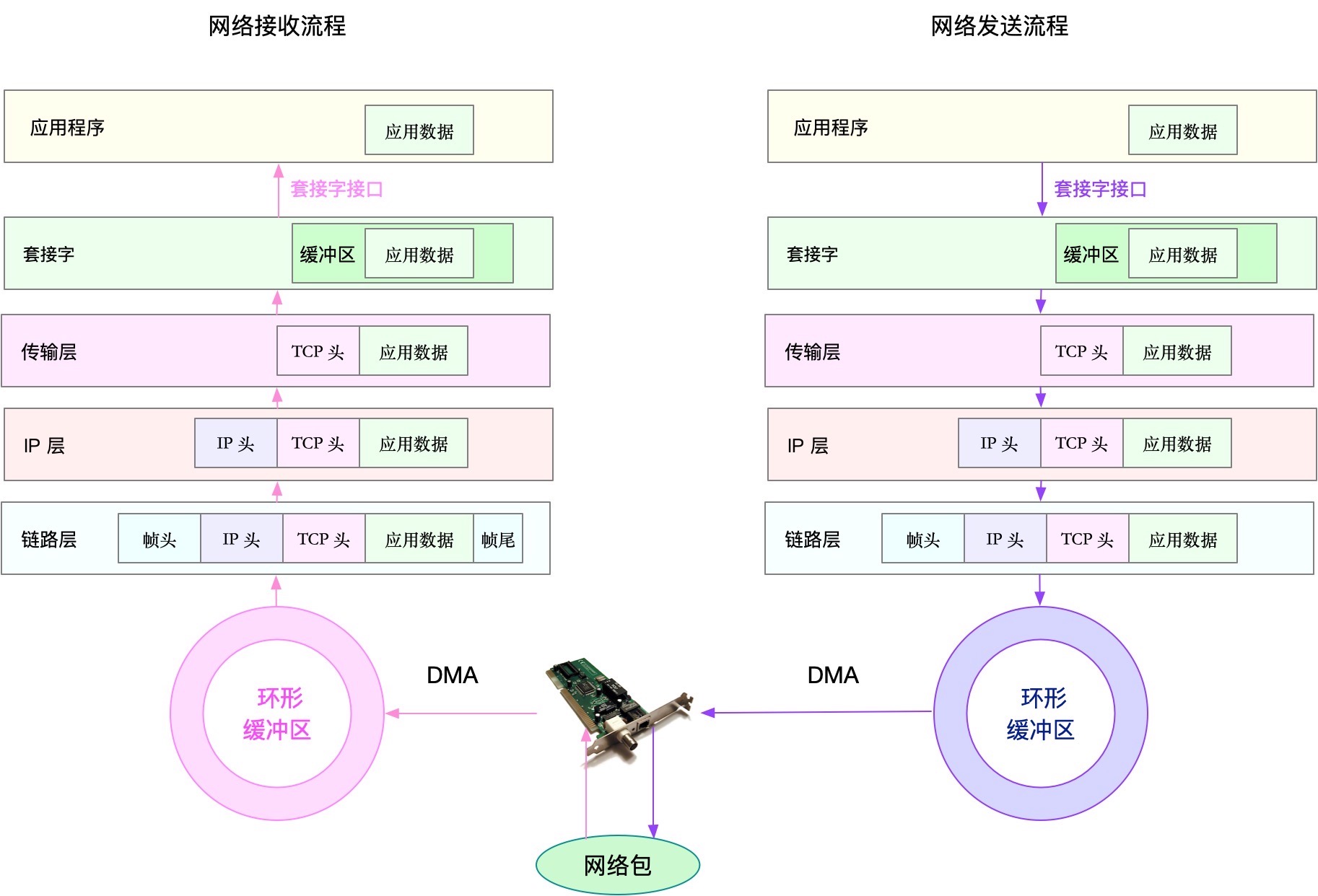
- 网络性能分析:不同的层关注不同的USE指标,如ss、netstat、tcpdump、bcc工具
- 链路层:关注接口吞吐、丢包、错误、软中断等角度分析
- 网络层:从路由、分片、叠加网络等角度进行分析
- 传输层:从TCP、UDP原理出发,从连接数、吞吐量、延迟、重传等角度分析
- 应用层:从应用层协议(http、dns)、请求数qps、套接字缓存等角度分析
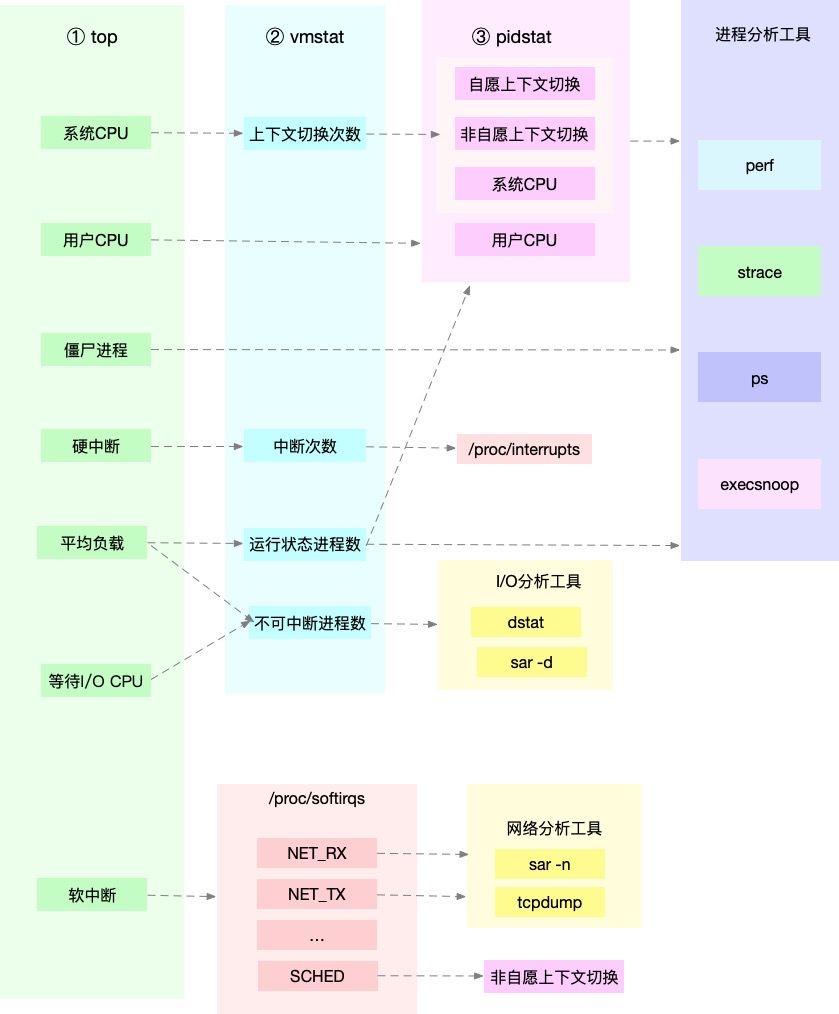
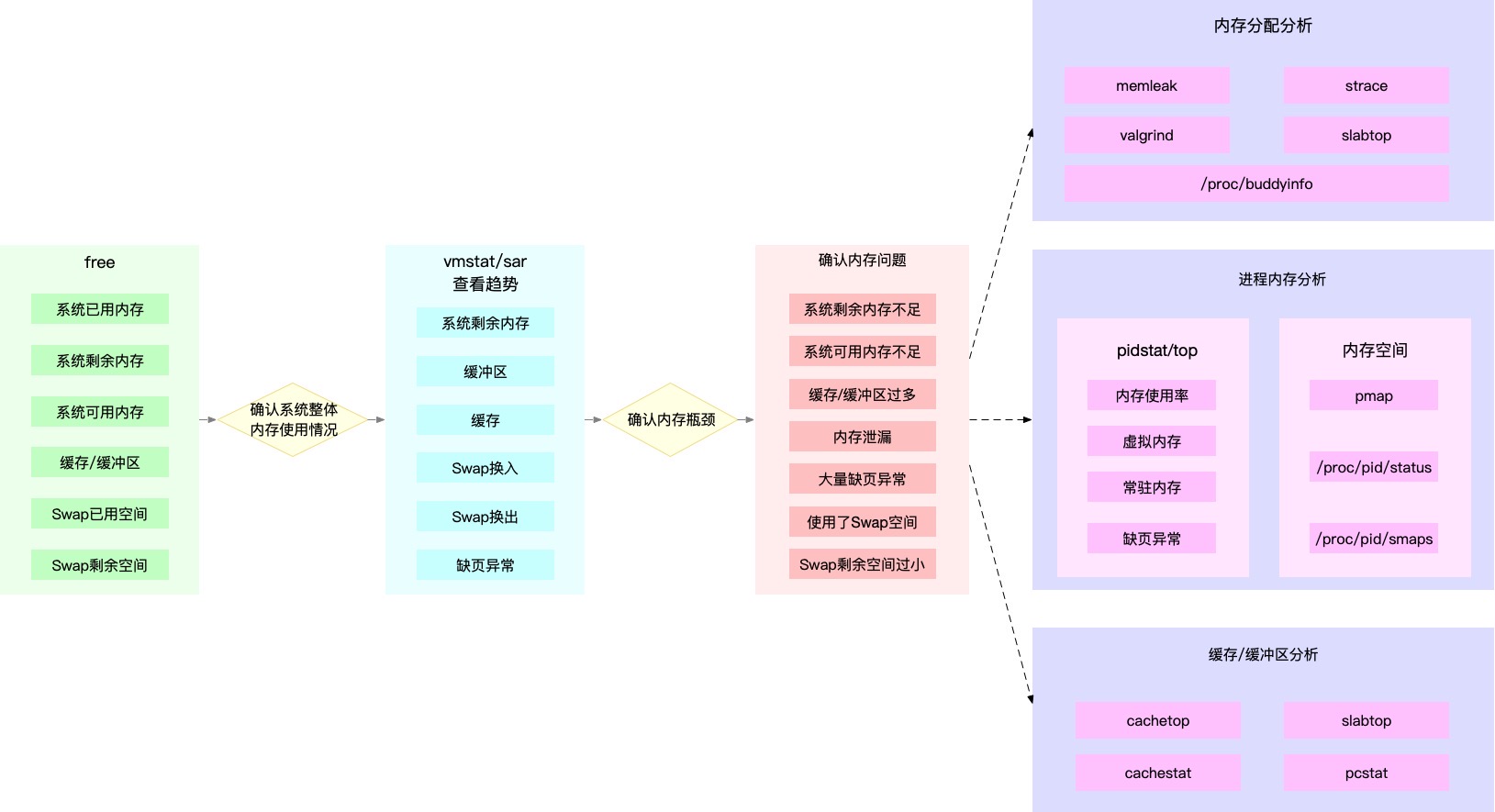
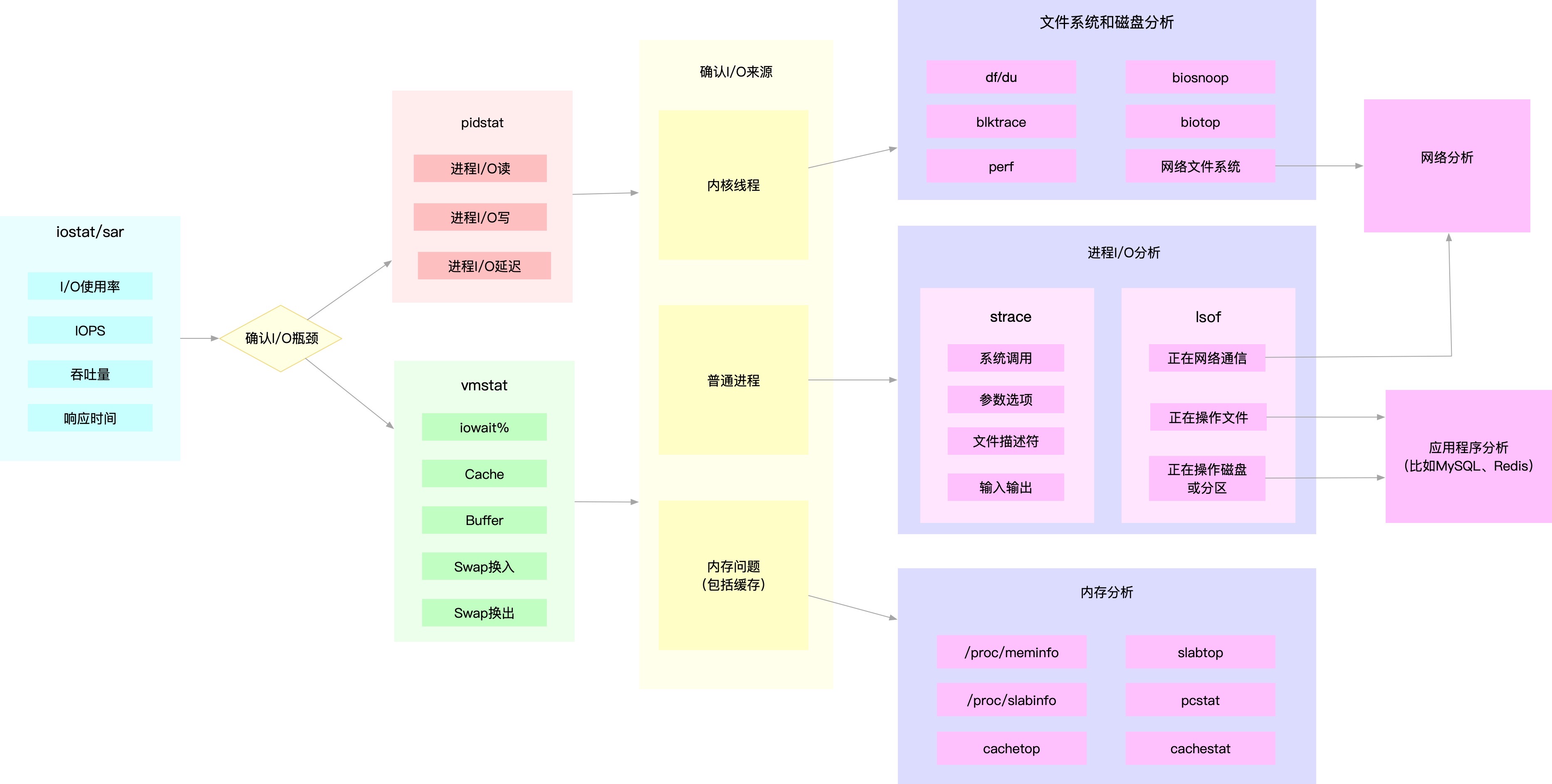
3.2. 应用程序瓶颈分析步骤
最典型的应用程序性能问题,就是吞吐量(并发请求数)下降、错误率提升、响应时间增大,分析下来总结为三类:资源瓶颈、依赖服务瓶颈、自身应用瓶颈;
- 资源瓶颈:利用系统资源瓶颈分析方式处理
- 依赖服务瓶颈:诸如数据库、分布式缓存、中间件等跨应用的性能问题,使用全链路跟踪系统,快速定位问题根源
- 应用性能问题:
- 不合理的应用设计,诸如多线程处理不当、死锁、业务算法的复杂度过高等,使用应用程序指标监控以及日志监控,观察和复现内部执行过程中的错误问题
- 利用strace观察系统调用;利用perf和火焰图,分析热点函数;使用动态追踪技术,分析进程的执行状态
4. 优化性能问题的一般方法
找到性能问题的真凶后,如何来优化?
4.1. 系统优化方法
- CPU优化:排除不必要的工作、充分利用缓存,减少进程间调度上下文切换带来对性能的影响
- 绑定CPU,CPU亲和性,减少进程间相互影响
- 为中断服务例程,开启中断负载均衡,利用CPU多核优势
- 使用Cgroups,为进程设定资源限制,避免某个进程消耗大量CPU
- 内存优化:解决内存不足、内存泄露、SWAP过多、缓存命中低缺页异常过多对性能带来的影响
- 除非有必要,Swap应该禁用,避免额外IO带来的内存访问变慢原因
- 利用Cgroups,为进程设置了内存限制,可以避免个别进程消耗过高内存,影响其他进程;对应核心应用,可以降低其
oom_score,避免被OOM杀死; - 使用大页、内存池,减少内存的分配和回收,从而降低缺页异常;
- 磁盘和文件系统IO优化:
- 提升读写性能:SSD替代HDD,或者使用RAID技术提升IO性能
- 结合应用IO特征,选择合适的IO调度算法,比如SSD和虚拟机中的磁盘,采用
noop调度算法,数据库则采用deadline算法 - 优化文件系统和磁盘缓存、缓冲区,比如调整脏页的刷新频率、脏页限额,以及内核回收目录项缓存的倾向等;
- 使用不同磁盘隔离不同应用的数据、优化文件系统的配置选项、增加磁盘预读、磁盘队列长度,也是优化思路
- 网络性能优化:
- 从内核资源和内核协议:
- 增大套接字Buffer、连接跟踪表、最大半连接数、最大文件描述符数、本地端口范围等内核资源配置
- 减少Timeout超时时间、SYN+ACK重传数、KeepAlive探测时间等异常处理参数
- 开启端口复用、反向地址校验,调整MTU大小降低内核分片负担
- 从网卡(网络接口)角度:
- 将CPU执行工作卸载到网卡执行,即开启网卡的GRO、GSO、RSS、VXLAN等
- 开启网卡的多队列功能,每个队列使用不同的中断号,调度到不同的CPU上执行
- 增大网卡的缓存区大小以及队列长度,提升网络传输的吞吐
- 极限性能下(C10M),绕过内核协议栈
- DPDK,直接在用户态进程用轮询方式(结合大页、CPU绑定、内存对其、流水线多种机制,优化网络包的传输效率)
- 内核XDP,在网络包进入内核之前,对其进行预处理
- 从内核资源和内核协议:
4.2. 应用性能优化方法 - 以始为终
应用性能优化最佳位置,是程序内部
- 举例:
- CPU使用率(sys%)过高:表象是系统CPU使用率过高,实际是应用不合理的系统调用,优化不合理的系统调用。
- CPU使用率高,IO响应慢:不合理的表结构或者SQL查询,导致大量IO操作以及内存聚合等行为
- 观察RED,请求数率、错误数、响应时间,以始为终:
- 单应用内部:
- CPU使用角度:简化代码、优化算法、异步处理、编译器优化
- 数据访问角度:使用缓存、COW(写时复制)、增加IO缓存和缓冲区大小,获得更快的数据处理速度
- 内存角度:使用大页、内存池、内存预分配,减少动态分配和回收,提供更好的内存访问性能
- 网络角度:使用IO多路复用、长连接替代短连接、DNS缓存,优化IO并减少网络请求数,减少网络延时带来的性能问题
- 进程工作模型:异步处理、多线程或多进程,充分利用每一个CPU的处理能力,提升应用程序的吞吐能力
- 架构角度:
- 使用消息队列、CDN、负载均衡等方法来优化
- 利用调度程序,进行负载均衡,将Job、请求分配到其他机器资源进行水平扩展后,在汇聚结果,如MapReduce、Nginx负载均衡Http请求
- 单应用内部:
5. 总结
应用性能优化是一个程序员避免不开的问题,监控是运维和应用性能分析的利器。
我们需要采集应用和系统的各种关键指标,通过系统监控、应用性能监控对我们的应用和系统资源进行态势感知,通过监控告警让我们知道对应故障产生,利用日志系统保存案发现场,帮助我们快速定位问题;
在系统和应用监控方面,可以通过Prometheus+Granfana很好的支持到包括CPU、内存、磁盘文件系统、网络资源的USE指标,以及应用系统的RED请求率、错误数、响应时间黄金指标,快速定位目前的应用和系统的范围情况;
进一步,我们可以利用Jaeger、Zpkin这类全链路跟踪分析工具,进一步对应用内部的依赖服务、核心处理逻辑等RED指标,进一步缩小性能问题的范围,最终定位问题产生的原因;考虑到排查过程中,会涉及日志分析,我们可以通过ELF或者EFK方式对日志系统进行部署,从而更方便的对日志进行检索,以便更快的定位问题;
最终我们可以结合系统和应用性能优化的方法,对我的应用和架构进行优化,最终达到应用性能指标可以提升的效果;
同时我们在做程序开发过程中,眼光可以稍微看长一些,前期的架构设计以及应用设计充分考虑到业务的一段时间的增长,这样以始为终的思维方式进行应用程序的开发和架构设计;
最后,我们需要记得一点,避免过早优化!