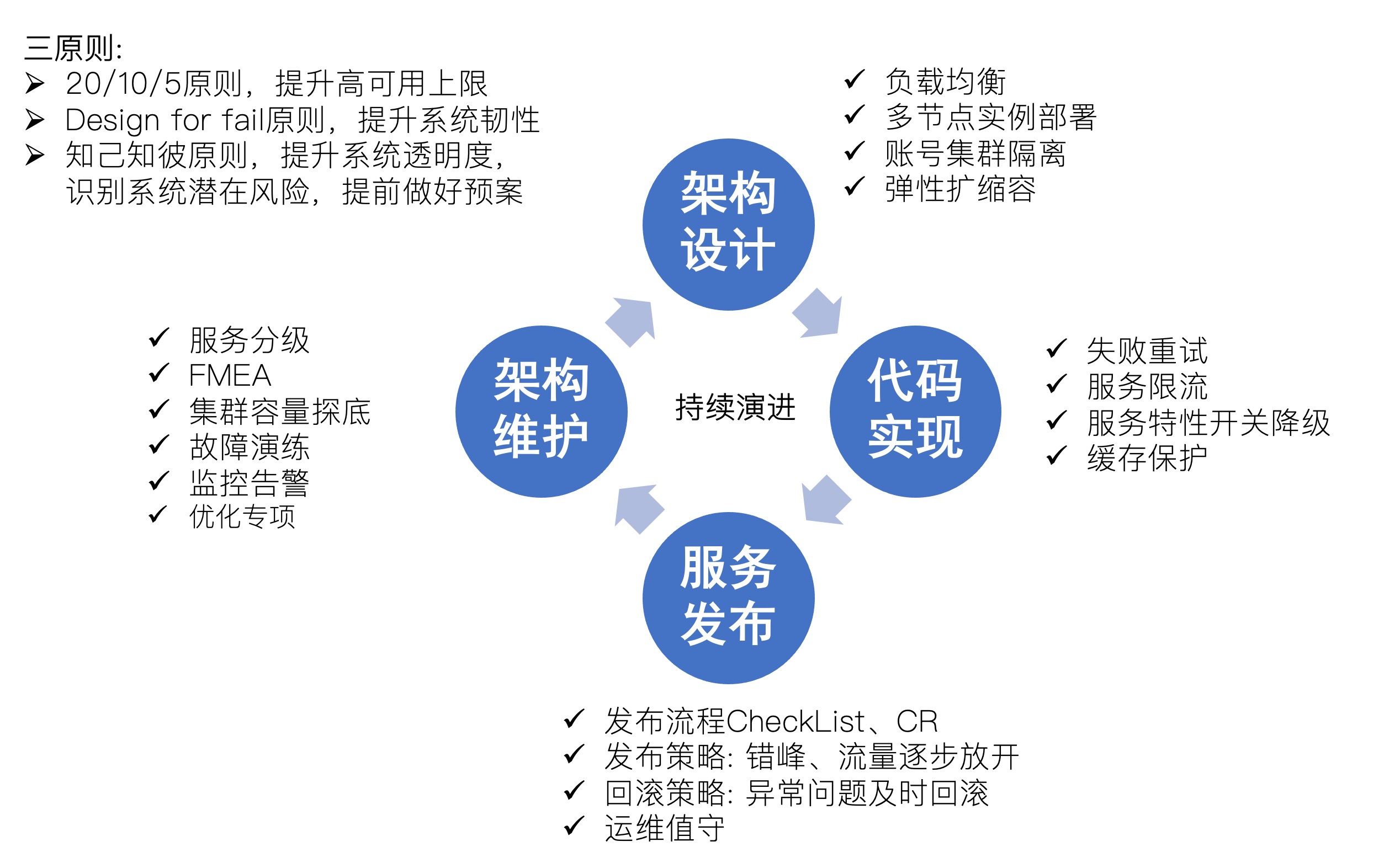
提高可用性,从全局,非单点技术,包括研发流程、团队文化也有影响 提审可用性是一个过程,需要长时间的积累,本章主要介绍高可用架构设计关键点
1. 概述
1.1. 可用性 vs 可靠性
- 可用性(N 个 9 表述): 系统可用的时间,以丢失的时间为驱动,公式:
PA=Uptime/(Uptime+Downtime)- Uptime: 系统可用时间
- Downtime: 系统不可用时间
- 可靠性: 系统无失效时间间隔,以发生的失效个数作为驱动,公式: PA=MTBF/(MTBF+MTTR)
- MTBF: 平均故障时间(mean time between faiulre)
- MTTR: 平均故障修复时间(mean time to repair)
可用性等级:
| 等级 | 几个 9 | 年停机时长 | 常用技术 | |
|---|---|---|---|---|
| 基本可用 | 99% | 87.6h | 负载均衡 | |
| 较高可用 | 99.9% | 8.8h | 灰度发布、快速回滚、自动化发布 | |
| 高级可用 | 99.99% | 53min | 微服务、数据库、缓存集群、容错、监控、弹性伸缩 | |
| 极高可用 | 99.999% | 5min | 异地多活、智能运维 |
1.2. 降低可用性原因
- 发布: 服务升级、数据迁移导致服务可能中断
- 故障: 服务 Bug、系统宕机、内存溢出、网络波动等导致服务可能中断
- 压力: 突发事件导致服务处理不过来,导致服务中断
- 外部依赖: 外部依赖服务故障,导致调用异常
1.3. 增加可用性的方法
- 20/10/5 原则,提升系统架构高可用的上限
- Design for fail 原则,提升系统韧性
- 知己知彼原则,提升系统透明度,识别系统潜在风险,提前做好预案
2. 服务发布
思考切尔诺贝利事件,流程操作规范的重要性
发布过程关注点:
- 发布流程 CheckList、CR
- 发布策略: 错峰、灰度流量逐步放开
- 回滚策略: 异常问题及时回滚
- 运维值守
2.1. 发布策略对比
2.1.1. 蓝绿部署

部署蓝绿两套集群,通过负载均衡关联,新旧蓝绿交替滚动发布,回退简单,负载均衡切换到旧版本即可(当存在数据隔离后,实际情况操作比较复杂)
- 自动化基础设施依赖
- 全面监控
- 两套环境隔离,有相互影响风险(比如: 存储服务无法很好蓝绿处理)
- 难点数据结构变更,如何同步数据,故障时候,如何回滚
- 支持流量快速切换(实际有困难)
2.1.2. 灰度发布/金丝雀发布

- 流程: 从负载均衡剔除节点(流量踢干净)、节点升级、自动化接口测试、加入负载均衡、监控故障、逐步灰度其他节点
- 意义: 减少故障范围、尽早用户反馈以及数据收集反馈
- 灰度控制: 内部->外部 1%->5%->10%->全网
2.1.3. 影子测试

基于日志、TCPCopy、MQ 消息发送一份做对比验证,存资源冗余的问题
3. 容错设计 Design for failure
容错设计是为了确保错误发生时,能够从容应对
3.1. 消除单点
- 服务冗余设计
- 服务应该无状态
- 能够做到出现问题故障转移(比如 lvs、nginx+keepalive、redis 哨兵、mysql 主从切换模式),通常会配合健康监测来做
3.2. 特性开关
常见分支模型:
- 基于 Trunk 模型(trunk based development) - 基于主干开发,Google、Facebook,避免拉分支合并分支影响
- 短生命周期分支(short livedfeature branches model) - 发布后合并主干
多个特性并行开发,通过switch特性开关控制服务是否开启,同时持续集成,还依赖代码 CR、单元测试、集成测试等
通过灰度引擎控制满足特征规则的用户才能看到新特性

3.3. 服务分级
产品功能梳理核心流程,找到核心服务,划分等级,确认服务关键程度
| 服务级别 | 划分依据 | 示例 |
|---|---|---|
| 1 级服务 | 核心业务流程,一旦故障业务遭受重大损失 | 注册、登录、买课、下单、支付、直播录播 |
| 2 级服务 | 用户体验影响严重,一旦故障,关键业务还可用,用户体验影响严重 | 搜索、评论、收藏、咨询 |
| 3 级服务 | 用户体验影响轻微,一旦故障,正常流程不受影响,不常用的功能不可用 | 推荐服务、个人信息、积分 |
| 4 级服务 | 多为管理维护,用户不受影响,用户不会直接访问 | 统计、排行、好评度等 |
3.4. 服务降级设计
- 服务降级前置条件是先梳理清楚服务核心等级,预先配置中心定义好降级开关
- 降级方式
- 关闭功能: 业务 JS 控制少掉了某个功能
- 请求短路:返回缓存数据
- 简化流程:注册成功的提示短信不发
- 延迟执行: 比如定时任务
- 关闭定时任务
- 低精确度返回:比如报名人数、在线人数
3.5. 超时重试
主调服务请求被动服务,可能存在成功、失败、超时 3 类状态,频繁发起重试,可能加重消费者负担,造成更严重的事故。
重试策略的关键因子:
- 超时时间: 包括调用超时时间、下游服务处理时间
- 重试总次数(retrycount):多次重试可能对下游造成更大压力
- 重试间隔时间(intervalTimey):间隔多久重试
- 重试间隔时间衰减(weakTime): 时间退避/衰减算法
重试模式:
- 简单重试:try-catch-redo,重试一次
- 策略重试: try-catch-redo-retry straegy,重试策略决定是否重试,关键因子(retrycount、intervalTimey、weakTime)
重试模式比较通用,尝试对业务解耦
- 何种条件重试: 符合指定策略才重试
- 何时重试: 立即重试、间隔重试、时间衰减重试、随机退避重试
- 重试次数:不超过重试次数最大限度重试
实现一个重试组件:
- RetrerBuilder,工厂模式创建重试策略的重试实例
- RetryIf,重试源定义(只在 xx 条件下才重试)
- WaitStrategy,重试等待策略定义(不等待、固定间隔、区间随机重试、指数退避重试)
- StopStrategy,重试停止策略(不考虑任务执行次数,如果超过了指定时间就停止重试)
- BlockStrategies:任务阻塞策略(sleep、锁、wait)
- Listener,监听器,重试后会回调注册的监听器
3.6. 隔离策略
- 进程、线程池
- 机器隔离
- 集群隔离
- 地域隔离
- 用户、租户隔离
3.7. 熔断器(防止雪崩)
服务雪崩:服务提供者的不可用导致服务消费者也不可用,并将不可用逐级放大的过程。 熔断器就是放在主调服务一侧,阻断主调请求避免对下游服务提供者造成压力。当被调大量超时下,主调服务主动熔断,防止服务进一步拖垮,一旦情况变好,主调重新尝试,最终让系统恢复
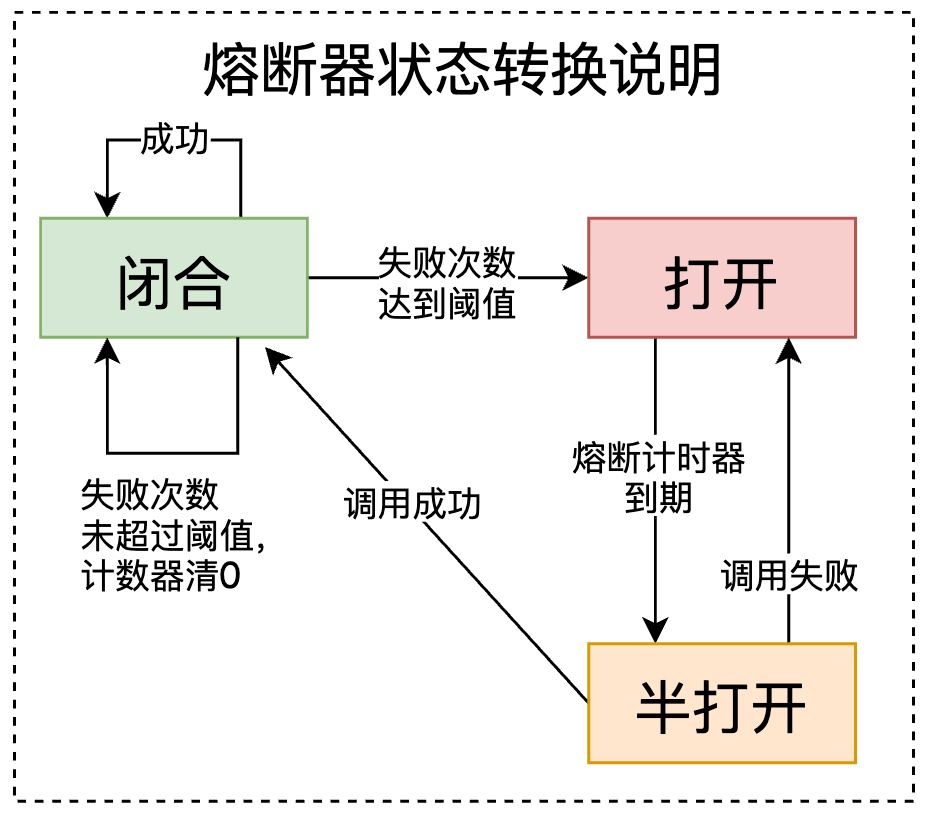
熔断器三种状态:
- 打开: 断路状态,调用请求被禁止,快速失败/业务降级返回
- 闭合: 通路状态,调用请求被允许放行;当在闭合下,区间时间内累计错误次数达到阈值,则将闭合状态变为打开状态,服务被熔断
- 半打开:熔断器允许部分请求到达下游,当在半打开下,若依旧有调用失败,则返回打开状态;若请求顺利,调用成功,则返回到闭合状态
注意:
- 禁止一个熔断器控制多个服务
- 熔断后,主调方应该做好快速失败、业务降级、不显示/显示缓存值返回
- 任务干预,支持通过开关预留,这次手动强制开启或关闭熔断器
4. 流控设计(过载保护)
流控,通过流量控制保护服务自身免被压垮,起到超出部分被拒绝,承受范围内请求被正常处理
4.1. 限流算法
4.1.1. 固定窗口(fixed window)
每个时间片内窗口内,允许访问的总次数。缺点是算法存在临界值 2 倍限流量情况,同时在下个时间片内出容易现流量蜂拥,容易形成踩踏现象
4.1.2. 漏桶算法(Leaky Bucket)
- 水流入(请求生产): 漏入桶中,桶满则溢出
- 漏桶(队列): FIFO 队列
- 水流出(请求消费): 以一定速率从桶内取出请求消费
适用场景: 秒杀场景,削峰填谷
4.1.3. 令牌桶算法(Token Buket)
一个时间窗口内通过的数据量,通过以 QPS、TPS 衡量
- 创建一个可放指定数量(M)令牌的桶(队列)
- 每间隔一定时间片,放入一个令牌到桶中(定时令牌生成器),桶满则溢出
- 每当 R 个请求到达时,从桶内取出 min(M,R)个令牌,若桶内令牌不够,则将请求缓存或者丢弃(对比网卡的环形队列作用)
4.1.4. 漏桶算法和令牌桶算法比较
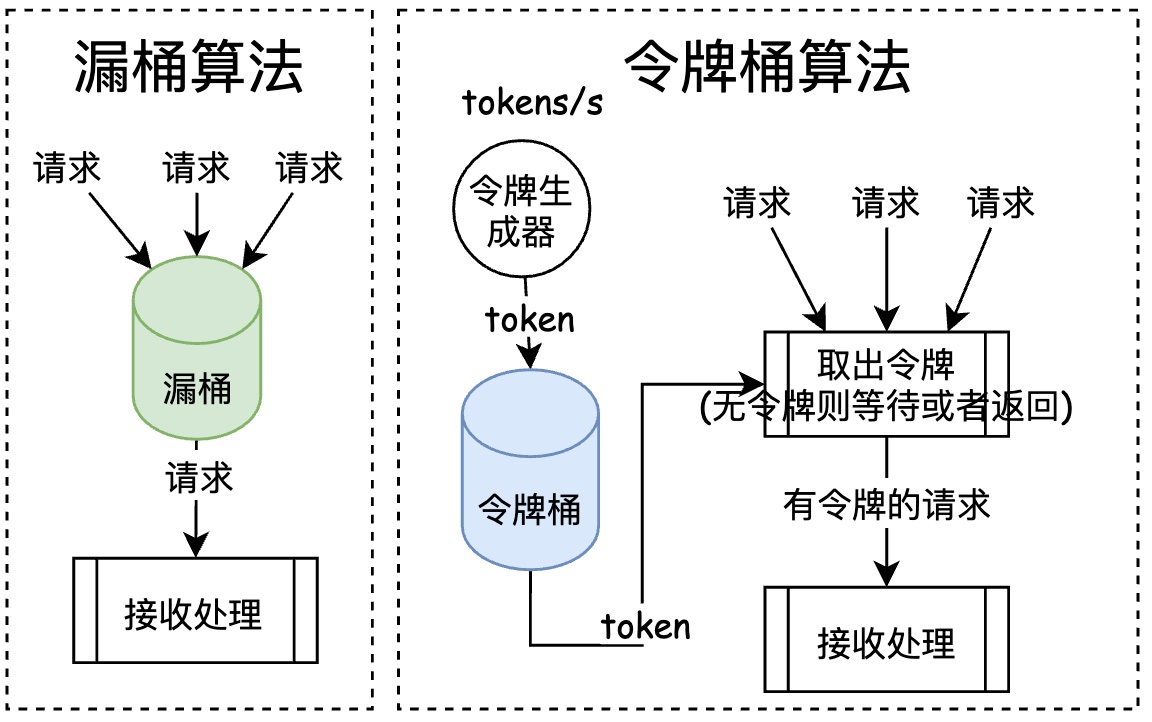
| 漏桶算法 | 令牌桶算法 |
|---|---|
| 不依赖令牌,不保存令牌 | 依赖令牌 |
| 桶满,则丢弃请求 | 桶满,丢弃令牌,可以选择暂存或者丢弃请求 |
| 不允许突发流量,多出被拒绝 | 允许突发流量,多出被暂存 |
4.2. 流控策略
需要配合压测结果、资源环境,对每个服务单独进行配置,一般采用经验值
流控的几点注意:
- 尽量在请求入口处做收拢,比如 GW 层(nginx)、业务出入口、公共基础服务
- 流控阈值的配置可能会随着服务的迭代也会变化,比如迭代后服务耗时增加了,那么对应的流控速率就应该更小了,这点需要注意
- 阈值不要设置过大,否则起不到流控作用
4.3. Nginx 的流控操作
nginx 流控用到的两个模块,分别限制 TCP 连接数和 HTTP 请求数:
ngx_http_limit_conn_module和ngx_http_limit_req_module
我们知道 nginx.conf 配置包含http{server{location{}}}三个层级,其中:
limit_conn_zone和limit_req_zone都只能配置在http{}limit_conn和limit_req可配置在http{}和server{}和locaiton{}3 个层级,表示针对用户进行全局、服务级、指定 URL 规则 3 个层级进行流控限制
4.3.1. ngx_http_limit_conn_module: 单 IP 连接并发控制
参考: http://nginx.org/en/docs/http/ngx_http_limit_conn_module.html
| |
PS: 1M 字节区域可以保留大约 16,000 个 key(64 字节状态)或大约 8,000 个 key(128 字节状态),如果满了采用 LRU 算法,桶满则请求被拒绝
4.3.2. ngx_http_limit_req_module: 单 IP 请求并发控制
参考: http://nginx.org/en/docs/http/ngx_http_limit_req_module.html
limit_req zone=name [burst=number] [nodelay | delay=number],burst、nodelay、delay 几个参数有兴趣的自己可以深入了解下
| |
4.4. 容量预估
对系统容量做到知根知底,ab、LoadRunner、Jmeter 这类都比较片面,很难系统模拟生产环境数据,采用全链路可以规避这些问题
全链路压测进行容量评估,几点注意:
- 核心流程:28 原则,确保真正核心的流程被压测到,这里就需要有张整体的服务调用网络拓扑图,并梳理出核心链路
- 隔离方式:独立压测环境,压测效果和隔离效果好,但成本高;生产混合,通过参数识别,在框架和服务处染色处理,资源隔离性不好;
- 缩小依赖范围:这样可以更加有的放矢,识别链路的关键瓶颈
PS: 链路有短板效应,需要准确的识别到链路的短板,方便后期做好性能提升,增加系统整体吞吐
5. 故障演练 - Chaos
The best way to avoid failure is to fail constantly
故障演练可以检测业务应用处理失败的能力,以及团队对故障的应对反应(包括通过监控日志、快速故障定位、应急措施),避免当故障真正发生时候,团队人员手忙脚乱,不知所措。
关键词: Chaos混沌工程
5.1. FMEA(失效模式与影响分析)
比失效模式与影响分析(英文:Failure mode and effects analysis,FMEA),操作规程,旨在对系统范围内潜在的失效模式加以分析,以便按照严重程度加以分类,或者确定失效对于该系统的影响
| 功能 | 失效模式 | 影响 | S(严重程度分级) | 原因 | O(出现频度分级) | 当前的控制措施 | D(检查分级) | CRIT(关键特性) | RPN(风险优先级数) | 行动措施建议 | 责任及目标完成日期 | 已采取的行动措施 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 账号登录 | 登录不上系统 | 无法登录,无法进行用户相关操作 | 8 | QQLogin 认证失败、查询默认资产账号失败 | 1 | 用户重新登录 | 2 | Y | 16% | 1、增加查询缓存 2、做账号集群隔离 | luping 2020/07/05 | 开始梳理认证相关问题 |
6. 数据迁移 - 目标是 Zero Downtime
- 逻辑分离,物理不分离
- 新老服务,双写同一个数据库/缓存不同表
- 过渡方案
- 逻辑分析力,物理分离
- 需要做数据同步,比如通过工具读取 binlog 实现数据双向同步
- 业务应用同时写两个库
- 老系统写消息通过写到消息中间件,消费消息中间件实现同步
关键问题: 数据一致性问题
7. 高可用的考虑点(3 个原则、4 个方面)
以一张图来汇总高可用相关知识点