1. 背景
之前的 Blog 都是基于 Hugo(一款静态站点生成软件)生成,内容主要为 Markdown,同时每个 MD 的顶部都有文章标题、关键字、分类、创建时间等信息(基于 Yaml 格式配置),格式如下:
| |
我遇到了两个问题:
- 一是很多 Blog 在写完后,并未对其进行摘要介绍,导致在首页展示的时候,都是空空如也(可以通过 Hugo 进行一些配置截取指定的部分),导致用户无法快速对 Blog 文章进行了解;
- 另外一点是关键字 SEO 搜索优化,之前的文章都没有关注这个关键词的问题,导致很多文章关键字和内容没有那么契合;
遇到两个问题后,可以一篇一篇修改,不过改动工作量很大,有没有简易一些方案?
从 OpenAI 出来后,就一直在使用 OpenAI 的接口做知识辅助(之前有介绍我是如何打造我的 OpenAI 研发辅助环境的,参见: https://tkstorm.com/ln/chatgpt-tips。 到此就引入了今天的主题,如何基于 OpenAI 对 Blog 文章进行总结,并自动替换掉 Hugo 的头部 Yaml 内容,集合 Hugo 的 Index 的模板修改后,就变成了下面的结果样子:

PS. 中间有一些 Go 基础代码、SQLite 的使用,不感兴趣可以直接跳过
1.1. 软件基础功能述求
项目动工前,结合自己的产品上的想法,梳理了下软件的基本功能:
- 递归处理整个目录下的 MD(为了测试需要,要支持传指定路径 MD 也可以)
- 代理网络支持,应用要能够走网络代理访问 OpenAI(支持应用配置网络)
- 能够动态配置 prompt,优化内容的 Summary 质量(通过文本配置化形式实现)
- 为了逐个文章做内容替换,要用到 Go 的正则、文本处理相关库,同时避免重复内容,需要记录并存已处理过的内容(通过文本或 DB 存储已处理过的内容)
- 考虑到整个目录有 200 多 MD,需要并行处理,提升处理效率
- 考虑软件的扩展(不单单只有 AISummary),考虑分层设计(选用 DDD 目录布局分层,这个布局是结合过往经验得到,参考即可)
大体的想法就如上,下面记录下一些软件的开发过程记录。
1.2. 整体流程
整体流程分成三大块:
- 项目入库部分,基本是参数的传入、配置文件读取
- 针对传入的文件或路径进行遍历,提取全量的
*.md文档,并行进行具体任务执行 - 针对具体每个 Blog 文档进行并发处理(提取、OpenAI 接口调用、替换)
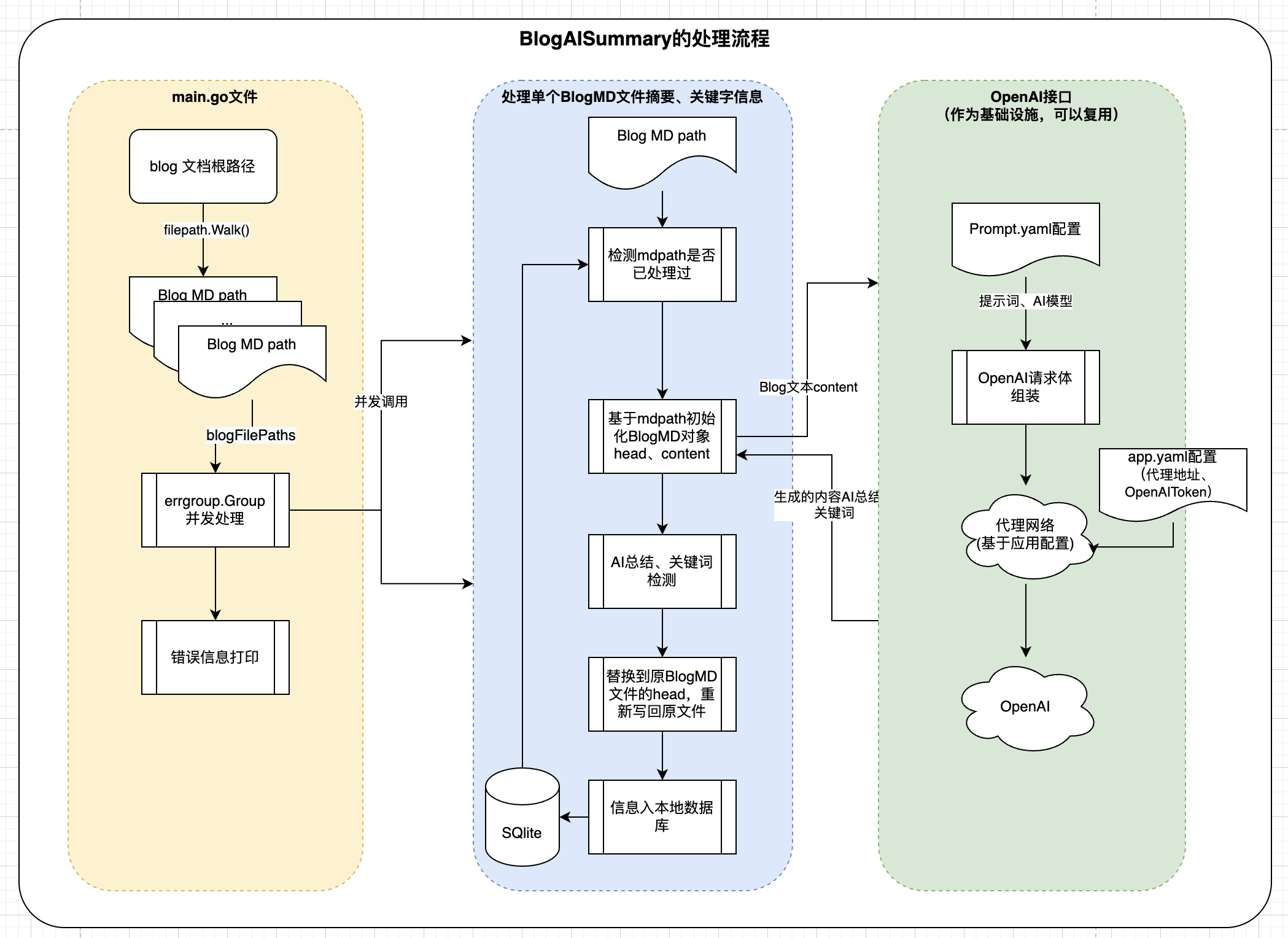
2. 项目实施日志
2.1. OpenAI 接口测试 - RapidAPI 测试
先简单的在 RapidAPI 上调通 OpenAI 的请求接口,如果存在网络问题,参考文章解决:https://tkstorm.com/ln/cloudflare-warp
RapidAPI: Rapid API 是一个方便易用的平台(之前名字为 PAW),为开发人员提供了快速访问和集成各种 API 所需的工具和资源,(我 MACOS 开发一直都是用的这款,一次买断很划算,很早以前就从 postman 转 RapidAPI,强烈推荐!)
RapidAPI 主要是用于 OpenAI 的 Restful 接口测试和快速验证:
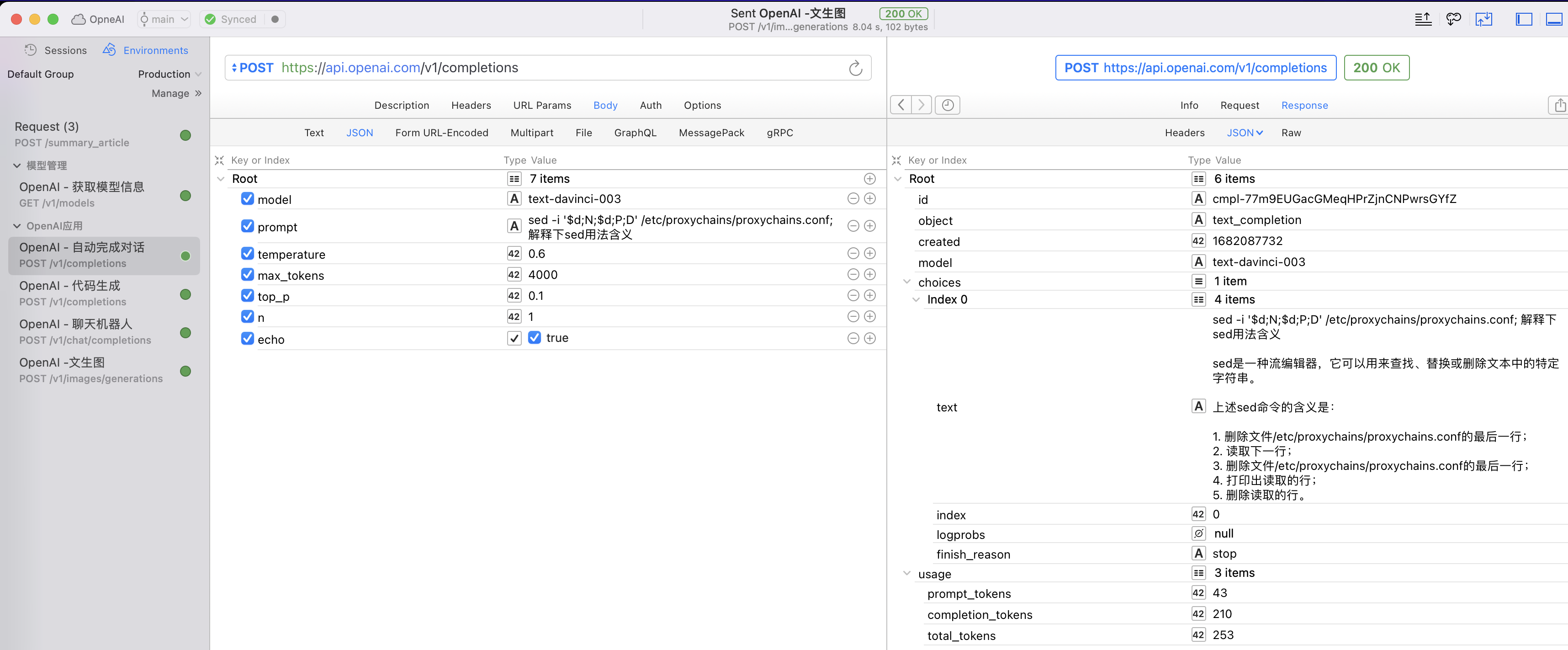
2.2. 仓库代码说明
仓库地址: https://github.com/lupguo/copilot_develop
目录结构:
| |
补充说明:
- BlogSummary 只是 Coplilot_Develop 项目的一个开始,后续
cmd目录下考虑到会添加更多其他的一些功能,所以这里暂不使用最顶层的main.go实现 - 关于 DDD 的文章讨论: https://tkstorm.com/posts/ddd-layout
2.3. Go - 并发相关(扇入扇出、资源泄露)
并发实际是一个比较大的话题,顺带复习了下以前看过的并发相关内容,简要记录了下,相关内容参考如下:
一些相关知识点内容:
2.3.1. Fan-out、Fan-in、通道未关闭、Goroutine 资源泄露问题
关闭通道与 panic 问题: 向关闭的通道上发送会出现恐慌
panic,所有可以通过sync.WaigGroup来达到并发的同步:wg.Add(len), wg.Done(), wg.Wait()Pipeline 模式:通过 Chan 通道连接不同的处理流程,每个流程的处理是一组相同的 Goroutines 执行,这些 Goroutine 会从上游接收值 → 数据处理 → 输出给到下游接收 Chan
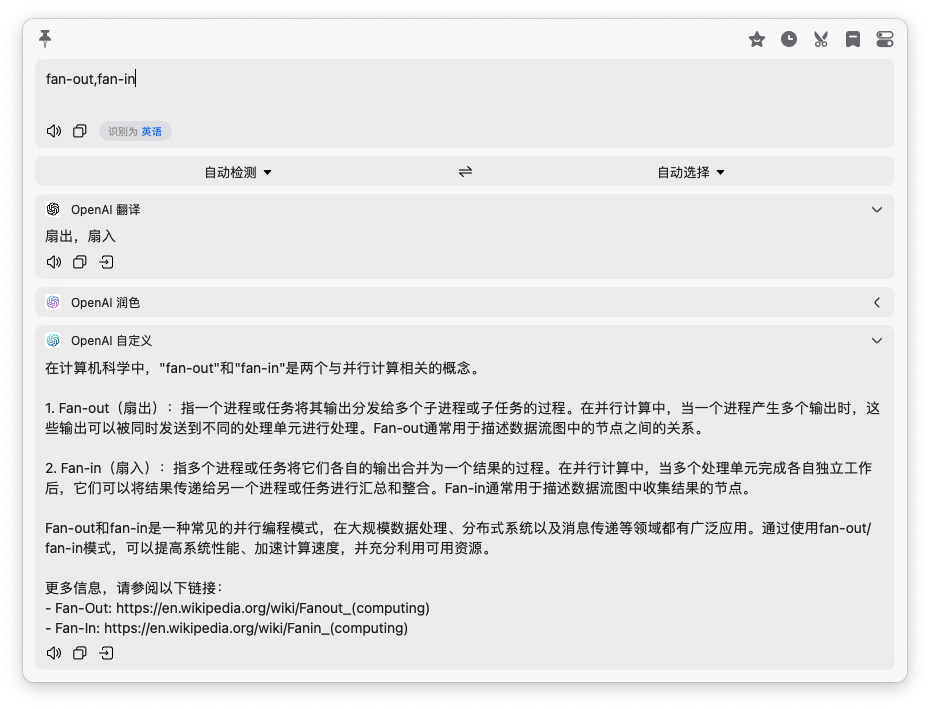
Fan-out,Fan-in:通过 Chan 做扇入和扇出,扇入后通过 range
- Fan-out(扇出):指一个进程或任务将其输出分发给多个子进程或子任务的过程(常见一个 RPC 调用,会分拆到多个基础 RPC 接口调用)。在并行计算中,当一个进程产生多个输出时,这些输出可以被同时发送到不同的处理单元进行处理。
- Fan-in(扇入):指多个进程或任务将它们各自的输出合并为一个结果的过程。在并行计算中,当多个处理单元完成各自独立工作后,它们可以将结果传递给另一个进程或任务进行汇总和整合。Fan-in 通常用于描述数据流图中收集结果的节点。
2.3.2. 资源泄露问题
| |
上述代码存在问题: 扇入处理的函数通过 range 不断读取 chan 内数据,直到该 chan 关闭,但可能存在上游 Goroutine 关闭 chan 的失败或异常的情况,导致 chan 通道未关闭,以至于扇入的程序无限期阻塞(上面的示例,如果 cs 中存在一个 chan 一直未关闭,那么 wg.Done 就无法执行,最终 merge 函数会一直阻塞),如果 merge 执行特别多次,就引发了资源泄露(描述符未做回收、Goroutine 的申请的资源未释放、变量因为还存在应用也导致无法被 GC 回收)
如何解决?:
通过配置有缓存区的 chan,
不带缓冲的 chan→带缓冲的chan,不过缓冲size大小不好确定1 2 3 4 5 6 7 8 9// 缓冲区chan,避免异常导致chan未能正常关闭 func gen(nums ...int) <-chan int { out := make(chan int, len(nums)) for _, n := range nums { out <- n } close(out) return out }采用
range通道时候,通过select从接收通道检测是否通道已关闭,如果已关闭则直接退出。因为从已关闭的通道上的接收操作,总是可以立即进行,并得到产生元素类型的零值。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52// 通过信号明确取消 - suggest func merge(done <-chan struct{}, cs ...<-chan int) <-chan int { var wg sync.WaitGroup out := make(chan int) // Start an output goroutine for each input channel in cs. output // copies values from c to out until c is closed or it receives a value // from done, then output calls wg.Done. // 扇入合并多个输入chan,扇入到out chan中,如果遇到任何意外(上游c没有正常关闭,导致range一直阻塞),output协程通过从<-done chan内收到结束信息,也会让out chan正常关闭 output := func(c <-chan int) { defer wg.Done() for n := range c { select { case out <- n: // 防止c case <-done: return } } } wg.Add(len(cs)) for _, c := range cs { go output(c) } // Start a goroutine to close out once all the output goroutines are // done. This must start after the wg.Add call. go func() { wg.Wait() close(out) }() return out } func main() { // 通过退出的done信号,可以广播给到所有的消费chan处理协程, done := make(chan struct{}) defer close(done) in := gen(done, 2, 3) // Distribute the sq work across two goroutines that both read from in. c1 := sq(done, in) c2 := sq(done, in) // Consume the first value from output. out := merge(done, c1, c2) fmt.Println(<-out) // 4 or 9 // done will be closed by the deferred call. }
2.3.3. 并发度控制,避免过多 Goroutine 处于等待状态
如果并发数量不加以限定,可能导致同时启动大量 Goroutine,即便 Goroutine 本身占用的资源小,但架不住大量的 Goroutine 因为获取不到 CPU 的资源,而处于等待状态,占用着系统资源
- 基于
sync.WaigGroup{}结合buffer chan做信号量控制并发的度 - 直接利用
errgroup.Group包,实际就是对上述流程的封装,但足够简单(推荐使用)
| |
2.3.4. 当前 Go 进程运行的协程数量打印
可以定期打印runtime.NumGoroutine()数量
| |
2.3.5. 管道使用指导原则
- 当所有发送操作完成,关闭通道 chan。管道中的每个阶段可能会阻止尝试向下游发送值,并且下游阶段可能不再关心传入的数据,关闭通道操作向管道启动的所有 goroutine 广播“完成”信号
- stages 任务处理阶段保持不断从入口通道接收值,直到这些入口通道关闭(
close(ch))或者入口通道被解除阻塞(通过select监听到指定信令后return退出)(参考 output 函数) - 通道 chan 通过增加 buffer 缓冲区容纳更多发送值,或者通过明确终止信号解除对方的阻塞
2.4. Go - 文件处理、字符处理相关
下面记录的是在开发过程中,涉及 Golang 标准库中 IO 相关操作
2.4.1. 文件 IO 读写操作
- 文件读写操作,
os.Open()和os.OpenFile()区别- 前者以
只读+创建模式打开,后者可以支持写入、清空等其他多种模式处理 os.Open()在文件或路径不存在时候会报错:no such file or directoryos.OpenFile(md.Filepath, os.O_TRUNC|os.O_WRONLY, 0644)这里的os.Flag需要注意:O_TRUNC表示清空文件后写入、O_WRONLY只写模式(还有O_RDONLY只读模式)、还有O_CREATE(文件不存在则创建)、O_SYNC(同步写入,默认写入文件缓存)、O_APPEND(增量写入,默认不加的话,从文件最开始位置写入)
- 前者以
filepath.Join()操作,做路径拼接- 临时文件生成
os.TempDir()tempFile, err := os.CreateTemp("", "exist_*.md")创建临时文件- 注意:临时文件最后要程序自己清理
- 清空文件方法:
os.Truncate()系统调用、利用 os.OpenFile()自定义系统 flag -os.TRUNC标识、文件可以写下打开模式
- 打开的文件句柄 file 支持通过
file.Name()获取路径名称 file.Close()操作,防止资源泄露:- 避免资源浪费,GO 的 GC 会自动回收(不过时间太长了),如果存在未关闭的 FD 过大,GC 压力将增大,同时 FD 的受操作系统的应用进程的 ulimit 限制,可能导致 FD 泄露应用进程无法打开更多的 FD 导致程序异常
- 如何检测文件是否为普通常规文件: 通过
os.Stat(filename)获取文件信息,然后通过文件的file.Mode()检测是否为常规文件- 通过
fileInfo, err := os.Stat(filePath)→fileInfo.Mode().IsRegular()检测
- 通过
- 如何获取文件的当前路径:
os.Getwd()操作
2.4.2. 字符串操作
如何从一个字符串中,截取到指定字符串的位置?
可以通过 idx :=strings.Index(s,sub) 检测是否 sub 在 s 中,不在返回 -1 ,然后通过 s[:idx] 返回
| |
2.4.3. bytes.Buffer 对象与 bufio 缓冲库
字节缓存库bytes.Buffer和 bufio 缓冲库很类似,后者支持将一个 io.Writer 或 io.Reader 库包装成缓冲库,支持最后 w.Flush()操作,可以减少系统调用次数
2.4.4. 程序执行耗时
| |
2.4.5. 标准输入输出接口
/dev/null 是 linux 中的特殊文件,可以通过 os.OpenFile("/dev/null", os.O_WRONLY, 0666) 打开黑洞文件,将 oldStdout := os.Stdout 保留后,将标准输出更换到黑洞文件 os.Stdout = devNul,执行完后恢复 os.Stdout = oldStdout
| |
2.5. Go - 正则处理相关
正则语法参考: https://github.com/google/re2/wiki/Syntax
这里在匹配 Hugo Blog MD 文档的 yaml 头的多行内容时候(参考文章开头格式),使用正则var blogMdRegex = regexp.MustCompile("(?sm)^---\n(.+?)\n---(?:\n+)(.*)$")
相关说明如下(第一个版本有 BUG,参考注释)
| |
2.5.1. 正则非贪婪匹配示例
| |
2.6. Go - 接口 Mock
以前是用的 uber 的 gomock 库: https://github.com/golang/mock,不过现在 Github 上面已归档了处于不再维护状态。
所以,我这里还是推荐改用 https://github.com/stretchr/testify 的 mock 库,基本流程也比较简单:
- 首先定义要 mock 的结构体(比如 DB、RPC、API 基础设施),嵌入
mock.Mock - mock 结构体实现接口方法,返回值依据后续传入的 args 参数进行断言(参见示例)
- 在用例中,实例化结构体,定于结构体要 Mock 的方法返回(参见示例)
| |
3. 数据存储
3.1. 为什么选用 SQLite
- 一开始想法是通过 file 文件来记录哪些 md 的文件已被更新何时更新,但会存在一些细节处理问题,比如文本之间的分割、特殊字符串处理等(考虑到后续
copilot_develp进一步迭代,进行一些其他更加复杂一些数据处理,还是用数据库存储更为方便),初步考虑下来,文件存在还是不如 DB 的结构化好维护 - 存储到 DB 又不想使用远程数据库,那么就优先考虑本地数据库了,调研下来
SQLite是不错的选择 - 另外,在 Golang 中使用
SQLite+GORM是很成熟的技术,同时选型SQLite数据库又是本地数据库支持,非常简便,即便后续要替换成类似MYSQL之类也比较容易,几乎不用动什么底层代码
综上几点,最终选用了SQLite+GORM
3.2. 如何使用 SQLite
虽然很久以前用过 SQLite,但还是如何操作基本都忘记了,不过我们不是有 OpenAI 工具么。
结合之前 Mysql 和 GORM 的操作,所以,很快就把 SQLite 的基础设施部分开发完了,一些图示:
3.2.1. SQLite 简要介绍
SQLite 是一种轻量级的关系型数据库管理系统(DBMS),它被设计为嵌入式数据库,可以直接嵌入到应用程序中使用。以下是关于 SQLite 的基本情况的介绍:
SQLite 简介:
SQLite 由 D. Richard Hipp 于 2000 年创建,它是一个开源项目,使用 C 语言编写。SQLite 的目标是提供一个零配置、零管理的数据库引擎,它不需要一个独立的服务器进程,而是直接访问存储在磁盘上的数据库文件。由于其简单性和高效性,SQLite 已经成为广泛使用的数据库解决方案。
应用场景: SQLite 适用于许多不同的应用场景,特别是那些需要在本地设备上存储和访问数据的应用程序。以下是一些 SQLite 常见的使用场景:
- 移动应用程序:由于 SQLite 的轻量级和嵌入式特性,它被广泛用于移动应用程序中,包括 iOS 和 Android 平台上的应用。它可以用于存储用户数据、应用程序配置和缓存等。
- 嵌入式系统:SQLite 适用于嵌入式系统,如物联网设备、嵌入式设备和嵌入式软件。它可以提供一个简单的数据库解决方案,用于存储和检索设备上的数据。
- 桌面应用程序:SQLite 也可以用于桌面应用程序,特别是那些需要本地存储数据的应用。它可以用于创建轻量级的数据库驱动的应用程序,如个人信息管理工具、笔记应用等。
- 测试和原型开发:由于 SQLite 的易用性和快速部署特性,它常被用于测试和原型开发阶段。开发人员可以快速创建数据库结构,并使用 SQLite 进行数据存储和检索。
注意事项:
- 并发性限制:SQLite 是一个单用户数据库,不支持多个进程同时对同一个数据库文件进行写操作。并发读取是支持的,但写操作需要进行锁定。因此,在高并发写入场景下,需要谨慎使用SQLite。
- 数据库大小限制:SQLite 对数据库文件的大小有一定限制,通常是几 TB。如果需要处理大型数据集或需要高性能的数据库操作,SQLite 可能不是最佳选择。
- 数据类型限制:SQLite 支持多种数据类型,但没有严格的数据类型检查。这意味着在存储数据时需要注意数据类型的一致性,以避免数据损坏或错误。
类似竞品: SQLite 在嵌入式数据库领域有一些类似的竞品,其中一些包括:
- MySQL: MySQL 是一个功能强大的关系型数据库管理系统,与 SQLite 相比,它是一个独立的服务器进程,适用于需要处理大量数据和高并发写入的场景。
- PostgreSQL: PostgreSQL 是另一个功能丰富的关系型数据库管理系统,它提供更高级的功能和更复杂的查询支持,适用于大型应用程序和复杂数据模型。
- MongoDB:MongoDB 是一个面向文档的 NoSQL 数据库,适用于处理非结构化数据和需要高度可扩展性的应用程序。
3.2.2. SQLite 具有的一些特性
- 轻量级:SQLite 是一个轻量级的数据库引擎,它的核心库非常小巧,占用资源少,适合在资源有限的环境中使用。
- 嵌入式:SQLite 可以直接嵌入到应用程序中,无需独立的服务器进程。它使用单个文件存储整个数据库,便于部署和管理。
- 无配置:SQLite 不需要复杂的配置过程,可以在没有任何额外设置的情况下立即使用。只需打开数据库文件,即可开始进行数据存储和检索。
- 事务支持:SQLite 支持 ACID(原子性、一致性、隔离性和持久性)事务,确保数据的完整性和一致性。它可以通过事务回滚来撤销未提交的更改。
- SQL 兼容:SQLite 支持标准的 SQL 查询语言,包括常见的 SQL 语句、数据类型和操作符。它还支持复杂的查询、连接和子查询等高级 SQL 功能。
- 跨平台:SQLite 可以在各种操作系统上运行,包括 Windows、macOS、Linux 和嵌入式系统等。它提供了多种编程语言的接口,如 C、C++、Java、Python 等。
- 零配置备份和恢复:SQLite 提供了简单的备份和恢复机制,只需复制数据库文件即可完成备份。这使得数据的备份和迁移变得非常方便。
- 小内存占用:SQLite 在内存使用方面非常高效,可以在内存受限的环境中运行。它可以通过调整缓存大小和使用内存模式来进一步优化内存占用。
- 支持扩展:SQLite 提供了扩展机制,允许开发人员编写自定义的函数、聚合函数和虚拟表等,以满足特定的需求。 这些特性使得 SQLite 成为一个简单、灵活且易于使用的数据库解决方案,适用于许多不同的应用场景。
3.2.3. SQLite 的安装
Mac 下如何检测是否安装了 SQLite?以及如何安装 SQLite?
| |
通用安装流程:
- 下载 SQLite:首先,你需要从 SQLite 官方网站(https://www.sqlite.org/download.html)下载适合你操作系统的SQLite预编译二进制文件。选择与你的操作系统和架构相匹配的版本进行下载。
- 安装 SQLite:解压下载的 SQLite 二进制文件到你选择的目录。在 Windows 上,你可以将 SQLite 文件放在一个易于访问的位置,如 C:\sqlite。在 Linux 和 macOS 上,你可以将 SQLite 文件放在/usr/local/或/opt/等目录下。
- 设置环境变量(可选):为了方便在命令行中直接使用 SQLite,你可以将 SQLite 的安装目录添加到系统的 PATH 环境变量中。这样,你就可以在任何位置使用 sqlite3 命令来启动 SQLite 控制台。
- 启动 SQLite 控制台:打开终端或命令提示符,导航到 SQLite 的安装目录(如果没有设置环境变量),然后运行 sqlite3 命令。这将启动 SQLite 控制台,并显示 SQLite 的版本信息。
- 创建或打开数据库:在 SQLite 控制台中,你可以使用 SQLite 的命令来创建新的数据库文件或打开现有的数据库文件。例如,要,可以运行以下命令:
3.2.4. SQLite 的 SQL 基本操作
| |
除了使用 SQLite 控制台,你还可以在你喜欢的编程语言中使用 SQLite。SQLite 提供了多种编程语言的接口,如 C、C++、Java、Python 等。你可以使用相应语言的 SQLite 库来连接和操作 SQLite 数据库。
3.2.5. SQLite 使用遇到的一些小问题
不支持表创建后调整表的列顺序,可以创建一个新表,从旧表查询数据插入新表,删除旧表,再重复一遍上面的操作
| |
4. 开发过程中的一些问题
4.1. OpenAI 相关相关
4.1.1. token 使用量消耗过大
因为通过 OpenAI 调用 AI 服务是按 token 收费的,所有可以考虑将一些无关紧要的字符移除,以减少 token 大小。
解决方案:这里我是将代码部分全部替换掉,仅保留文字以减少 OpenAI 的 token 使用量,因为 Blog 大部分内容仍然是文本信息,代码部分缺失不影响整个文章内容的摘要提取,目前对比看下来效果没有什么影响。
4.1.2. token 过长超过了模型的最大阈值
因为 Blog 的 md 中只有一篇有这个问题,暂时没有投入继续处理。
解决思路:可以将 token 过长的请求文本,考虑拆分成多个文本分别请求 OpenAI,得到结果后再喂给 OpenAI(有点类似 LangChain 的思想)
4.1.3. OpenAI API 接口限频问题
token 限频问题,执行过程遇到每分钟超过阈值问题?
解决思路:考虑 Token 技术+滑动窗口设计(后续有时间再考虑):
- 即每分钟固定阈值的 Token,每次 OpenAI 调用后,扣除对应的令牌桶令牌,到下一分钟重置令牌桶中数据
- 如果令牌桶中潜在资源过少,则阻塞下一个 AISummary 协程的并发处理,直至令牌桶中数据重置的通知
5. 最后
5.1. 与 AI 协同工作和学习
通常我们开发过程中也会遇到一些类似文章开头的问题,面对一个像解决的问题,我们有自己的初步想法,但实现过程中会存在一些知识盲区。
以往,当我遇到类似问题我基本会通过 Wikipedia、Google、StackOverflow、官方文档查阅,然后综合系统理解后给出解决方案,最后问题解决。虽然查阅资料和笔记过程会有技术的积累沉淀与技术成长,但效率还是蛮慢的。
现在,当我遇到了一个我不清楚的问题或者概念,会先通过 OpenAI 了解这个问题物的概念是什么、应用场景是什么、竞品是什么、有哪些优势和劣势等,实际就是 SWOT 分析,然后在让 OpenAI 结合对应的场景,给出可选的解决方案(就比如这次我对 SQLite 的使用 case),针对一些偏更深层次的内容,会通过 Google、Github、Medium 等平台去寻找一些最新相关的讯息,然后我会将这些信息通过 Notion 给记录下来,最终沉淀到自己的知识体系内,内化为自己的经验。
总之,我发现目前已经习惯了有 OpenAI 辅助研发、阅读、翻译、编程的场景了,无论是从知识的系统性学习,还是工作还是学习的效率都有蛮大的提升(趁手的工具很重要)! 所以面对新的知识,善用 OpenAI - What,Why,How! 自从 OpenAI 推出这大半年以来,在遇到自己盲区的问题,大约 70%以上问题我会优先考虑使用 OpenAI 来协同解决,怪不得之前 OpenAI 出来时候,Google 的搜索股价大跌了一波.
5.2. OpenAI 使用技巧
- 网络问题是基础设施必须要解决的,参考之前写的 cloudflare-wrap 那篇文章: https://tkstorm.com/ln/cloudflare-warp
- 选择配套的趁手的 AI 辅助工具很重要(包含账号注册等),参考之前写得 chatgpt-tips 那篇文章,后续也会持续更新: https://tkstorm.com/ln/chatgpt-tips
- Prompt 提示词,这个对你问题得到的结果准确性影响很大,可以参考之前写的 chatgpt-prompt: https://tkstorm.com/ln/chatgpt-prompt
- OpenAI 接口,可以尝试用 OpenAI Restful 接口进行一些基本的辅助开发,后续可以进一步结合
langchain之类的进行深层次应用(这部分还在探索阶段) - 基于 OpenAI 开发一些应用,并定期输出到 Blog 进行总结(这部还在进行中)
5.3. OpenAI 费用问题
目前主要是通过 OpenAI 进行接口请求,配套的ChatGPT-Next Web的Mac客户端(很好用),个人日常使用平均每月在 5 美刀左右(通过 Nobepay 充值),比 20 美刀每月的 ChatGPT 体验还有流畅度要好很多。
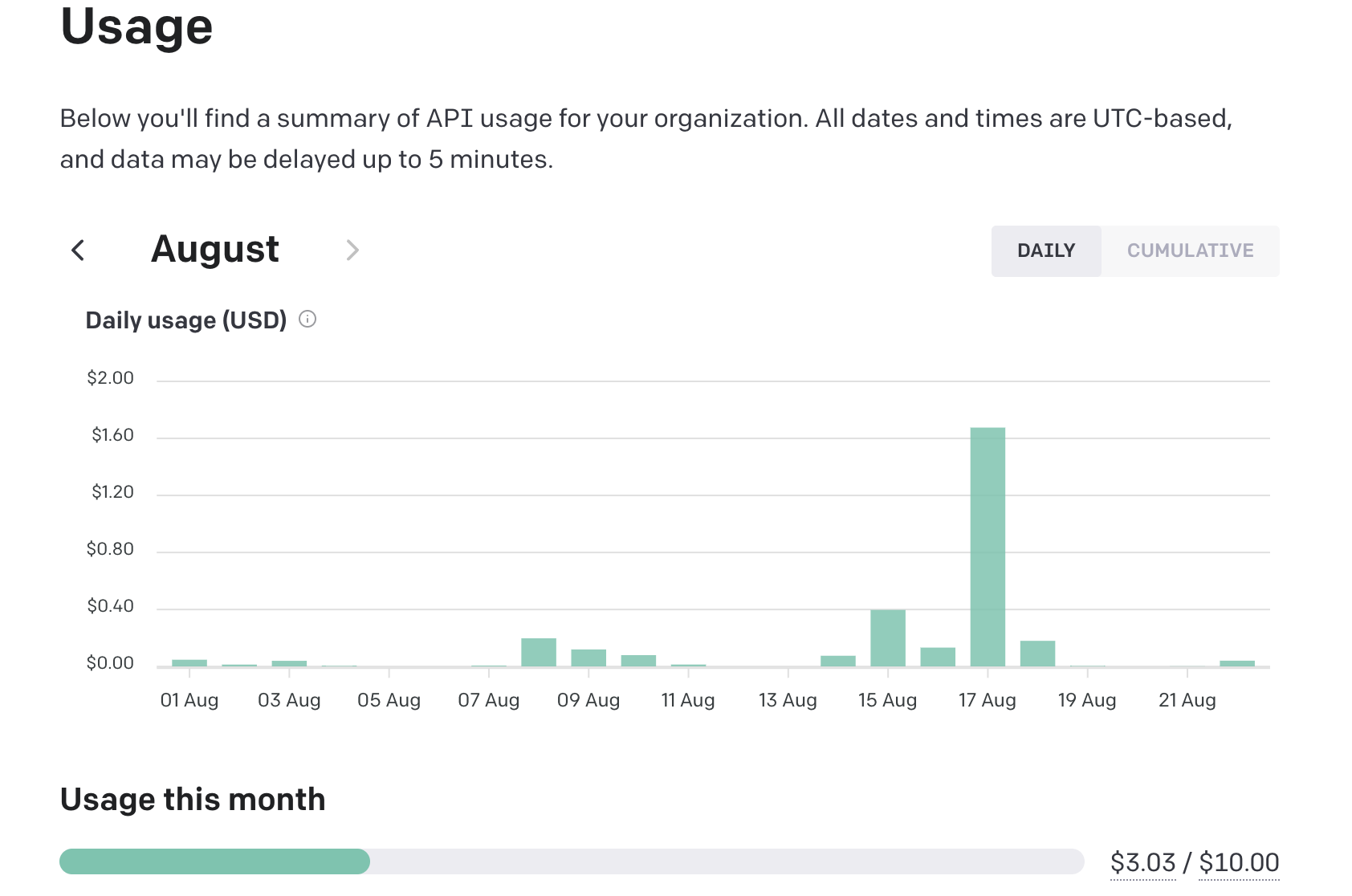
5.4. 个人 AI 日常工具截图
这里简单罗列了个人常用的几款 AI 高频辅助工具,有兴趣的自己可以尝试下~
5.4.1. ChatGPT-Next Web: 一个 OpenAI 的 Mac 客户端(强烈推荐)
5.4.2. Popclip+Bob+OpenAI: 翻译+Wikipedia 的组合
5.4.3. glarity summary : 一个 Chrome 插件,支持汇总文章摘要、重要信息
