1. 背景
从 2025 年年初到现在短短几个月时间,经历了 DeepSeek R1、GROK 3、ChatGPT o4-mini、Gemini 2.5 Pro\Flash、QWen3 等一系列模型,每当模型发布后,就会告知大众自己的 LLM 模型数据集跑分如何,非常有电脑组装后跑分的即视感。
作为普通开发者或用户,更多希望是自己在工作学习中,如何去选择适合自己的模型,决策依据无外乎模型能力、价格、Token 速度进行一个取舍,有点像架构设计里面的 TradeOff 架构选型。
问题是虽然知道这些要对比的关键要素,如何获取这些数据和信息是一个问题。
我自己在 LLM 关注过程中也走了一些弯路,接下来我会简要介绍下 LLM 的基准测试集合、模型能力对比以及一些对比网站分享
2. 基准测试(benchmarks)
大型语言模型(LLM)的能力通常通过标准化测试来评估,这些测试被称为基准测试(benchmarks),简单理解为各种跑分任务。
这些基准测试包含样本数据、用于测试 LLM 特定技能的问题或任务集、评估性能的指标以及评分机制,通过这些测试,研究人员和开发者可以衡量模型在不同任务上的表现,从而了解模型的基础语言能力、复杂推理能力和编程能力。
2.2. 数据集介绍
2.1. 常见数据集含义和测试目的
| 数据集名称 | 数据集含义 | 测试目的 |
|---|---|---|
| MMLU | Massive Multitask Language Understanding | 评估模型在跨学科任务上的多任务准确性,涵盖人文、科学、工程等多个领域的知识和理解能力。 |
| GPQA | Graduate-Level Scientific Question Answering | 评估模型在研究生级别科学问题上的推理能力。 |
| HumanEval | Python Code Generation | 评估模型生成 Python 代码的能力。 |
| MATH | Large-scale dataset of math problems | 评估模型解决数学问题的能力,包含 7 个不同的难度级别。 |
| BFCL | Benchmark for Function Calling | 评估模型调用函数/工具的能力。 |
| MGSM | Multilingual Grade School Math | 评估模型在多语言环境下的数学能力。 |
| HellaSwag | Commonsense NLI dataset | 评估模型在常识推理方面的能力,特别是完成句子或情景的能力。 |
| BIG-Bench Hard | Subset of BIG-Bench tasks | 评估模型在需要多步推理和常识的任务上的能力。 |
| SQuAD | Stanford Question Answering Dataset | 评估模型在给定文章中回答问题的能力。 |
| IFEval | Instruction Following Evaluation | 评估模型遵循指令的能力。 |
| MT-Bench | Multi-turn benchmark | 评估模型在多轮对话中的表现,包括理解上下文、生成连贯回复等。 |
| GSM8K | Grade School Math 8K | 评估模型解决小学数学问题的能力。 |
| MedQA | Medical Question Answering | 评估模型在医学领域的问答能力。 |
| PubMedQA | Biomedical Question Answering | 评估模型在生物医学领域的问答能力。 |
| PyRIT | Python Risk Identification Tool | 评估模型在安全相关的任务和风险识别方面的能力。 |
| Purple Llama CyberSecEval | Cybersecurity Evaluation | 评估模型在网络安全领域的表现。 |
| Perplexity | Measures how well a language model predicts a sample of text | 评估模型预测序列中下一个词的能力,反映模型的流畅性和对语言结构的理解。 |
| BLEU | Bilingual Evaluation Understudy | 评估机器翻译的质量,通过比较机器翻译文本与人工参考译文的相似度来衡量。 |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation | 主要用于评估文本摘要和机器翻译的质量,衡量生成文本与参考文本之间的重叠度。 |
| METEOR | Metric for Evaluation of Translation with Explicit ORdering | 评估机器翻译的质量,考虑了词语的同义词、词干和词序等因素,比 BLEU 更全面。 |
| CIDEr | Consensus-based Image Description Evaluation | 主要用于评估图像描述生成的质量,衡量生成描述与人工参考描述之间的一致性。 |
| SPICE | Semantic Propositional Image Caption Evaluation | 评估图像描述生成的质量,侧重于描述的语义准确性和完整性。 |
| BERTScore | Evaluates text generation by comparing generated text with reference text using BERT embeddings | 利用 BERT 模型的嵌入来衡量生成文本与参考文本之间的语义相似度,能够捕捉更深层次的语义信息。 |
| MoverScore | Measures the distance between two texts using Earth Mover’s Distance on their token embeddings | 衡量两个文本之间基于词嵌入的语义距离,能够评估文本的流畅性和语义相关性。 |
| BARTScore | Evaluates text generation using BART model | 利用 BART 模型来评估生成文本的质量,可以用于多种文本生成任务的评估。 |
| GPT-4 Score | Evaluation using GPT-4 as a judge | 使用 GPT-4 模型作为评估者来判断生成文本的质量,可以进行更主观和细致的评估。 |
| G-Eval | Generative Evaluation | 一种生成式评估框架,利用 LLM 本身来评估生成文本的质量,可以根据特定的评估标准进行评估。 |
| FActScore | Factuality Score | 评估生成文本的事实准确性,衡量文本中事实性错误的程度。 |
| SHEEP | Safety, Honesty, Ethics, and Privacy | 评估模型在安全性、诚实性、伦理和隐私方面的表现。 |
| BOLD | Bias in Open-ended Language Generation | 评估模型在开放式文本生成中存在的偏见。 |
| BBQ | Bias Benchmark for QA | 评估模型在问答任务中存在的偏见。 |
| ToxiGen | Dataset for evaluating toxicity in language models | 评估模型生成有毒或有害内容的倾向。 |
| TruthfulQA | Measures the truthfulness of language models in answering questions | 评估模型回答问题的真实性,衡量模型产生错误信息的程度。 |
| HONEST | Dataset for evaluating honesty in language models | 评估模型的诚实性,衡量模型是否会产生欺骗性或误导性的内容。 |
说明:
- 上述数据集均旨在评估 LLM 在不同维度(如知识、推理、编程、数学)的能力,难度和复杂性各有侧重。
- MMLU-Pro 和 GPQA Diamond 更注重广度和专业性,Humanity’s Last Exam 强调综合性,LiveCodeBench 和 SciCode 聚焦编程能力,AIME 和 MATH-500 则针对高级数学推理。
- 表格信息基于提供的网络参考,部分细节可能因数据集更新而略有变化。
3. 模型能力对比
3.1. 个人整理
2025 年以前,LLM 里面基本上是 OpenAI 一家独大,当时会关注它哪些模型最具性价比,从最开始的ChatGPT 3.5到ChatGPT 4o mini,再到4o-nano。
2025 年初自 DeepSeek 面市来,带 Reasonning RL LLM 不断涌现,这时候开始了不同模型之间的性价比对照。
DeepSeek 出来不久,当时自己还整理了 OpenAI 和 DeepSeek 以及模型价格和能力对比,可以看到当时4o-mini相比在非推理模型方面仍然很有优势(大多数普通日常任务已经足够好用)
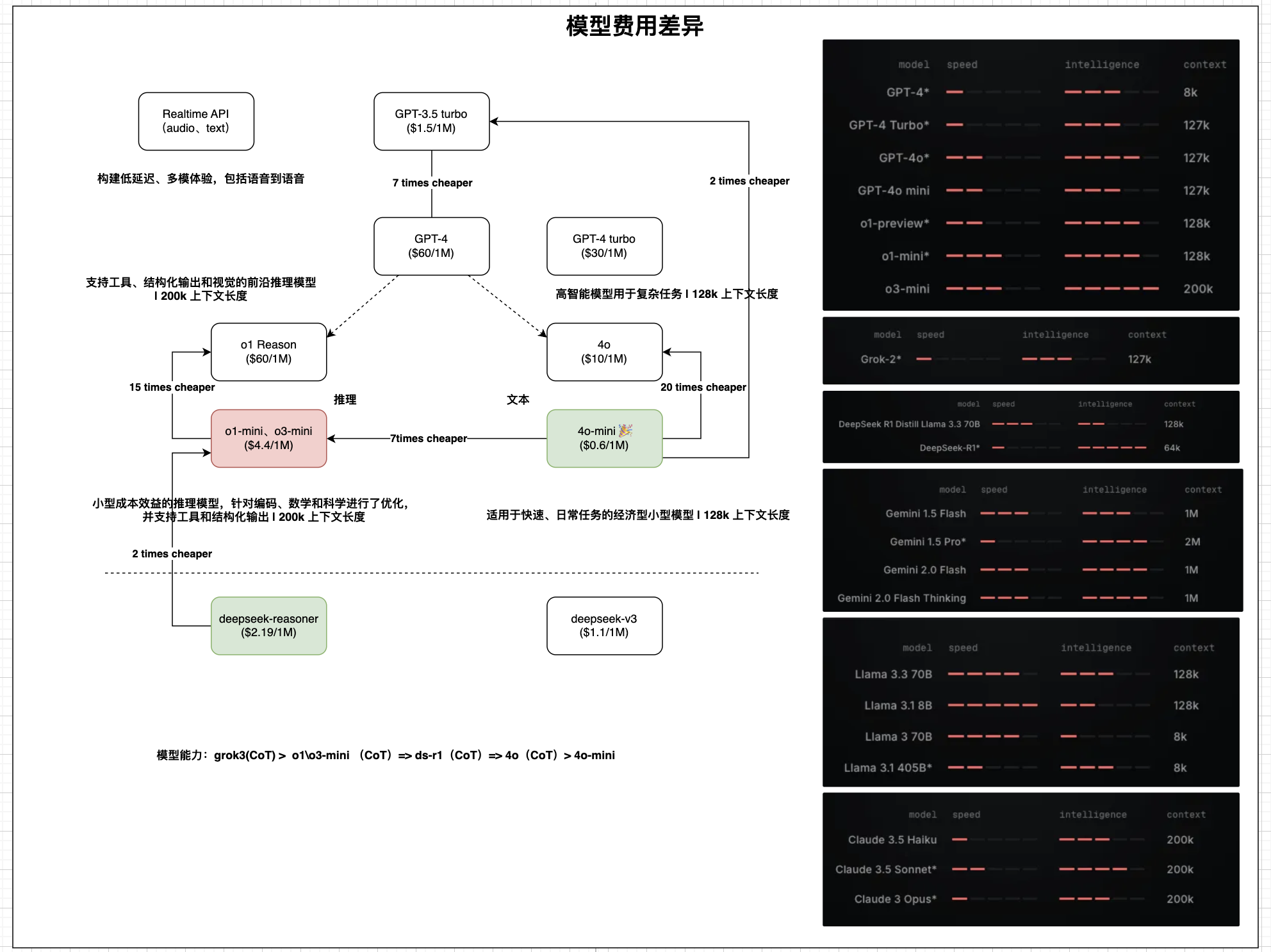
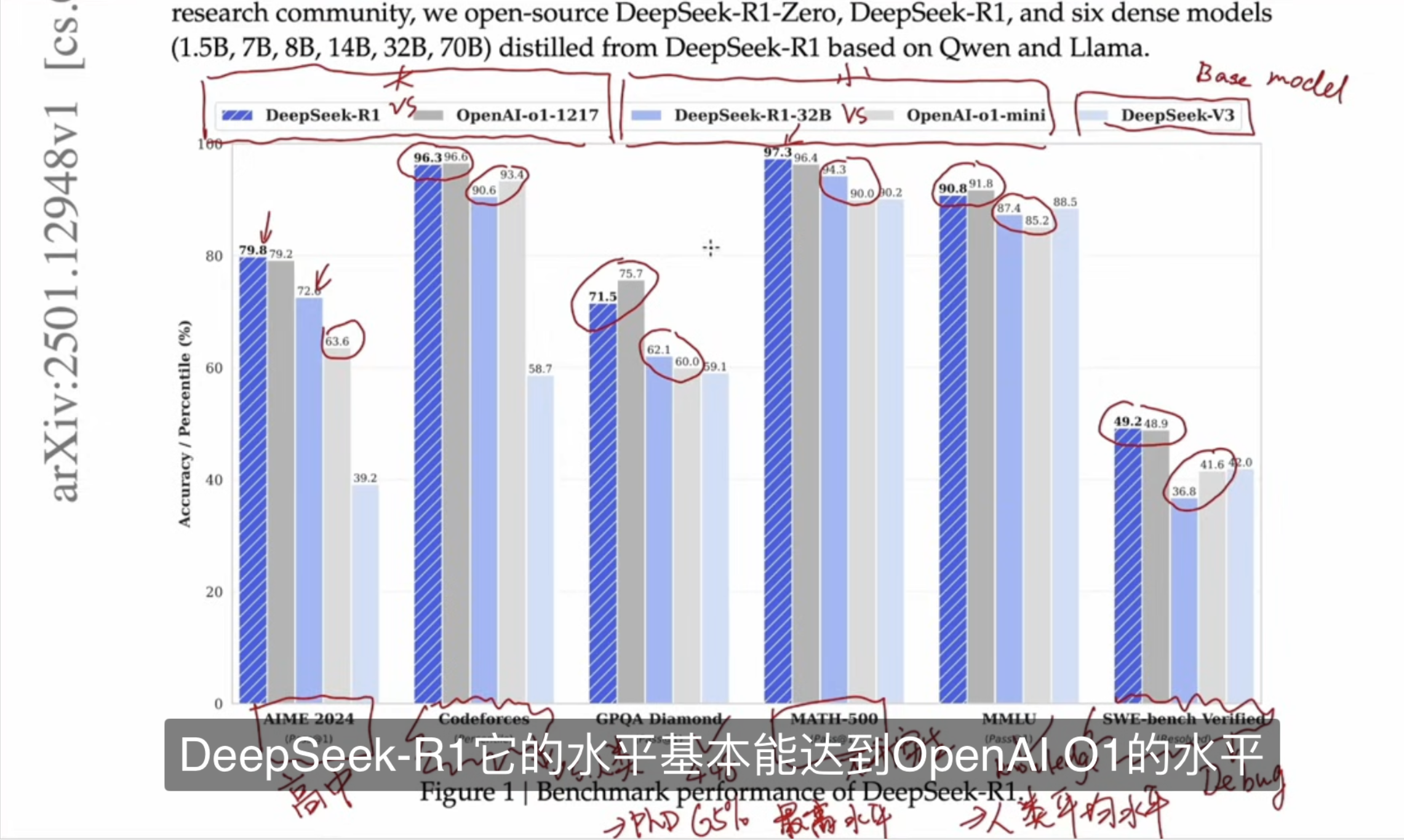
3.2. DeepSeek 官网整理
截图来源于EZ Encoder大佬视频分享,大佬当时在讲解这段时候,特意有标注和说明了数据集的含义,我这里直接截图 Share 过来了
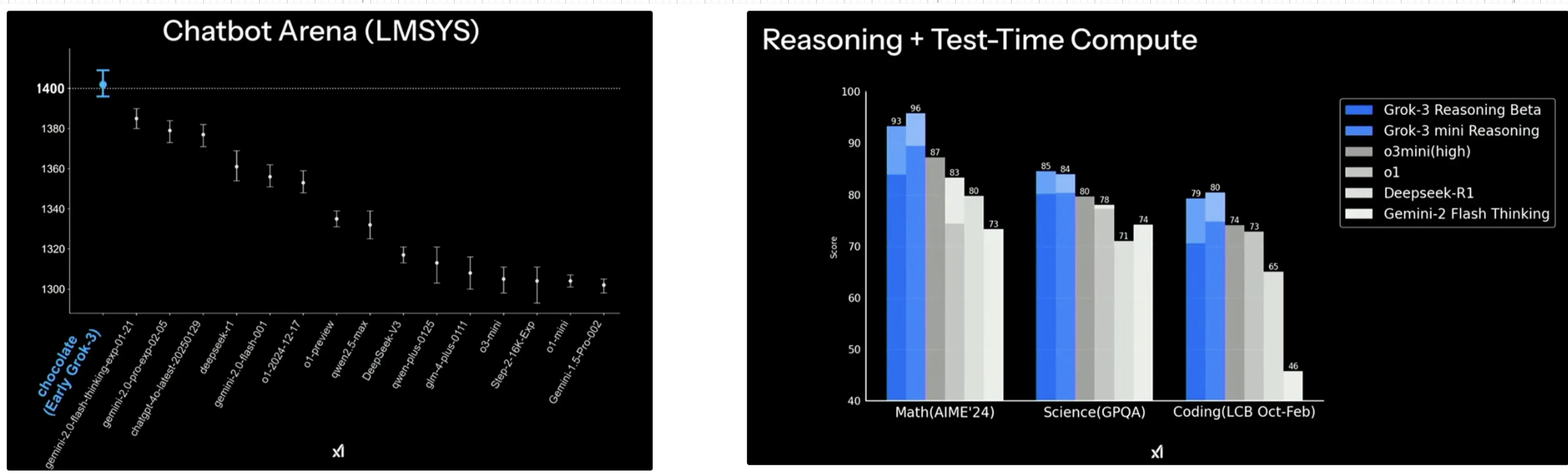
3.3. Grok3 发布会期间,分享的一些模型能力对比
下面是当时 Grok3 发布会的一些截图,可以看到也是(LMSYS 评测得分第一)
PS. Chatbot Arena是一个用于基准测试 LLM 的平台,其核心机制是让用户与两个匿名模型进行随机配对的对话,然后由用户投票选出他们认为更好的那个模型
4. 模型能力对比网站分享
上面铺垫那么多,实际主要分享两个网站:
4.1. artificialanalysis.ai
模型能力综合对比
网站开宗明义,直接聚焦模型能力、Token 输出速度、Price 价格三块:
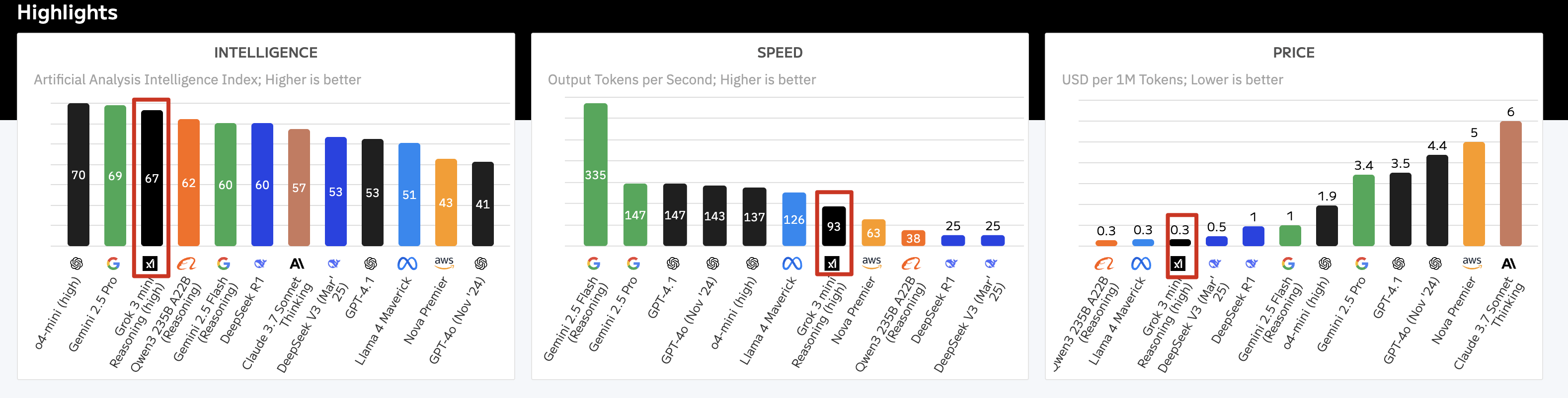
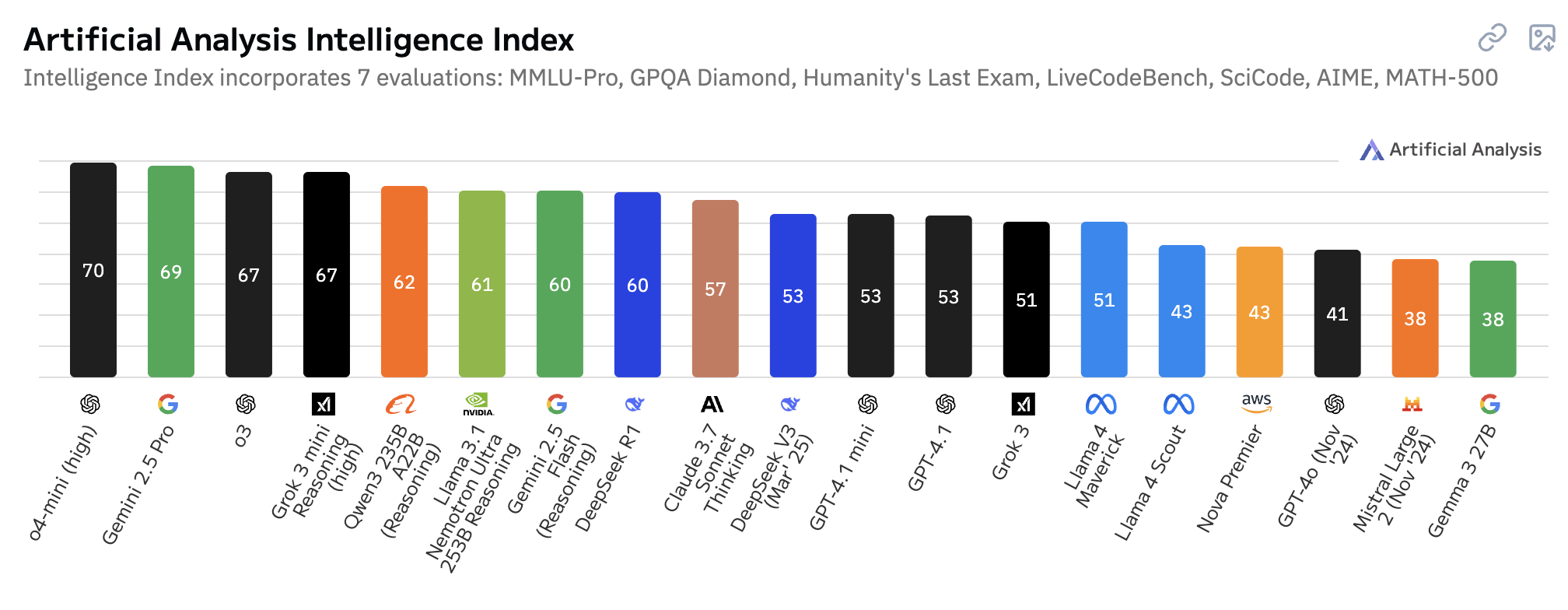
模型智力对比
涵盖数据集: MMLU-Pro、GPQA Diamond、Humanity’s Last Exam、LiveCodeBench、SciCode、AIME、MATH-500
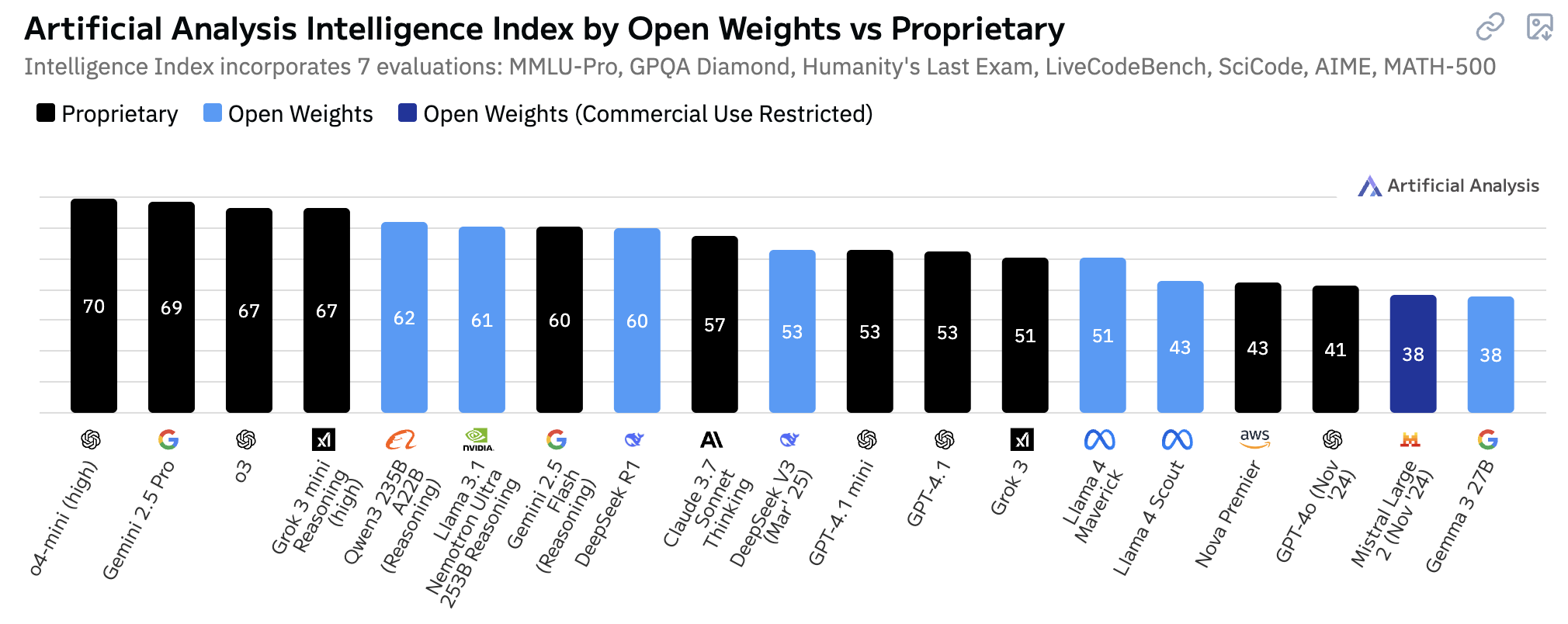
推理模型 vs 非推理模型智力对比

开源 vs 闭源模型对比
开源里面Qwen3 235B A22B (Reasoning)非常不错了,要是速度更快一点就更牛逼了!
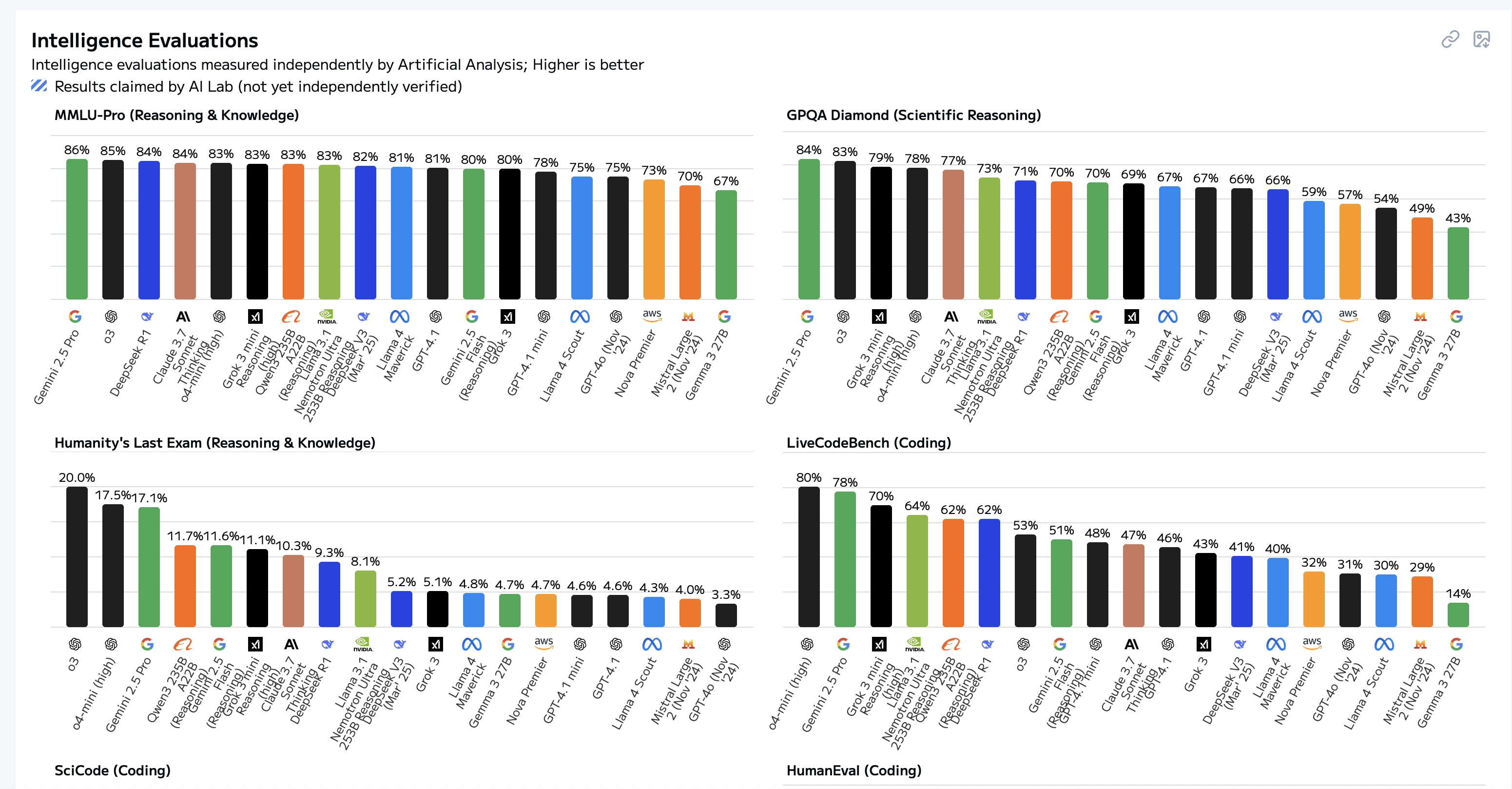
不同的数据集也有很好的对比
4.2. huggingface.co
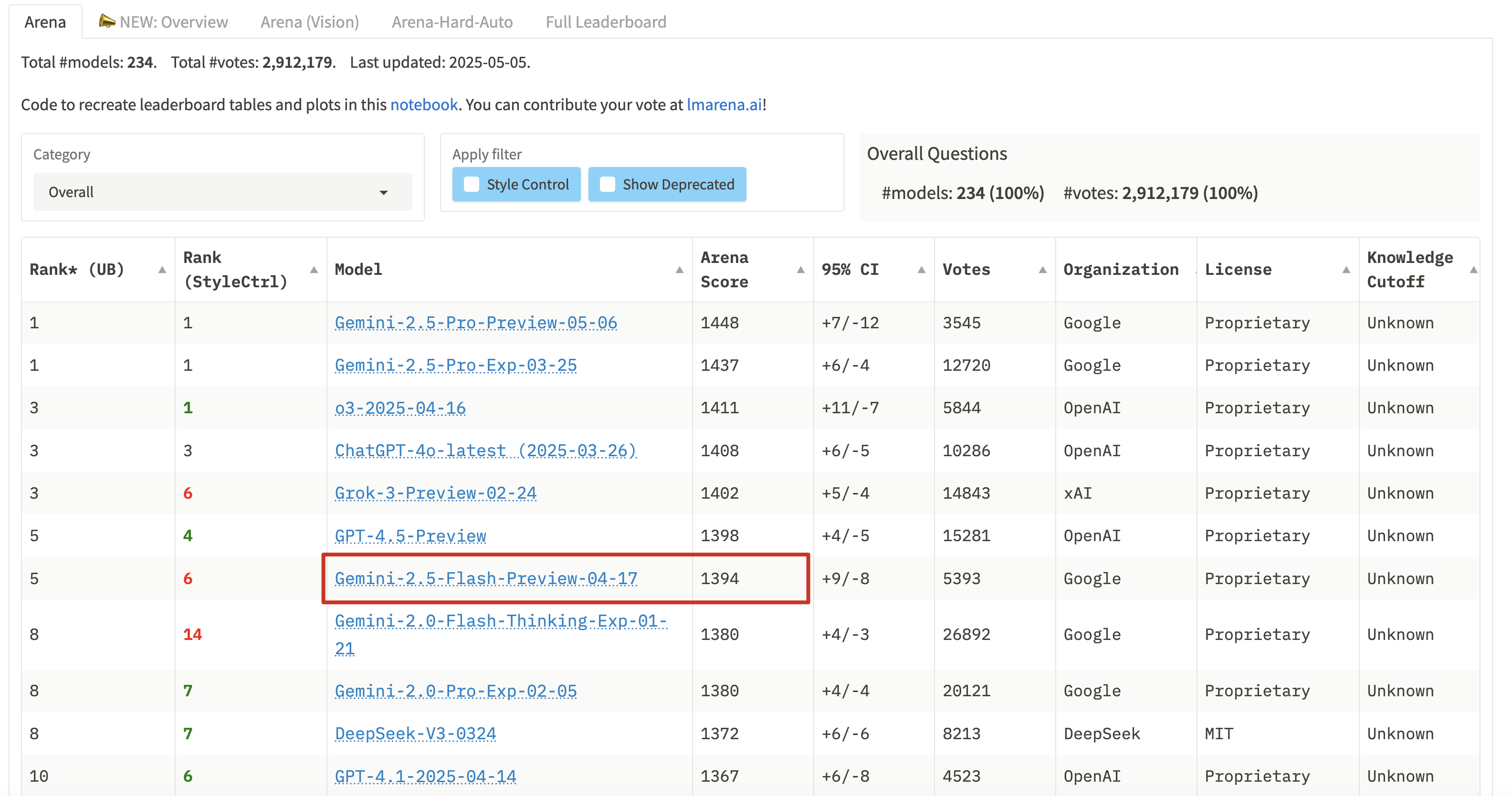
Huggingface 社区投票最好的 LLM 模型排行: https://huggingface.co/spaces/lmarena-ai/chatbot-arena-leaderboard
这里我把 Google 的圈出来了,最近在适用过程中发现Gemini-2.5-Flash效果的确蛮不错的,回答质量和速度相比 DeepSeek 还是要快很多;
结合在artificialanalysis.ai的图,也可以看到Gemini-2.5-flash拥有最快的 Token Speed
5. 小结
简要分享了 2 个 LLM 模型对比网站,一个是https://artificialanalysis.ai,另一个是https://huggingface.co/spaces/lmarena-ai/chatbot-arena-leaderboard,以及对 LLM 数据集的简要介绍,希望对接触大模型的同学有一些帮助。
国内 LLM 模型 API 的 SaaS 服务比较混乱(个人感觉),云厂商之间的模型也存在套壳、蒸馏、量化版本差异等情况,加上国内缺乏对 LLM 模型标准化基准测试,导致开发者的选型更多是倾向于头部 AI LLM 模型选择。
实际上,在不同的任务下结合对应场景选择合适的模型,LLM 效果和速度都会比直接选择大而全更好,简单的例子就是翻译、总结与复杂任务拆解、Coding 代码生成任务在推理和非推理模型之间选择的区别,
前者一般用非推理模型(比如GPT-4o-nano)模型就非常出色了,后者可以选择推理模型(比如R1、Gemini 2.5 pro,再结合 chatbox prompt 结果对照基本就大差不差了。
最后,我自己在日常工作和学习中 LLM 使用率:Grok3 > Gemini > DeepSeek R1 > GTP-4o-nano,付费 API 调用情况下,大部分会选择mini和nano版本已经足够。
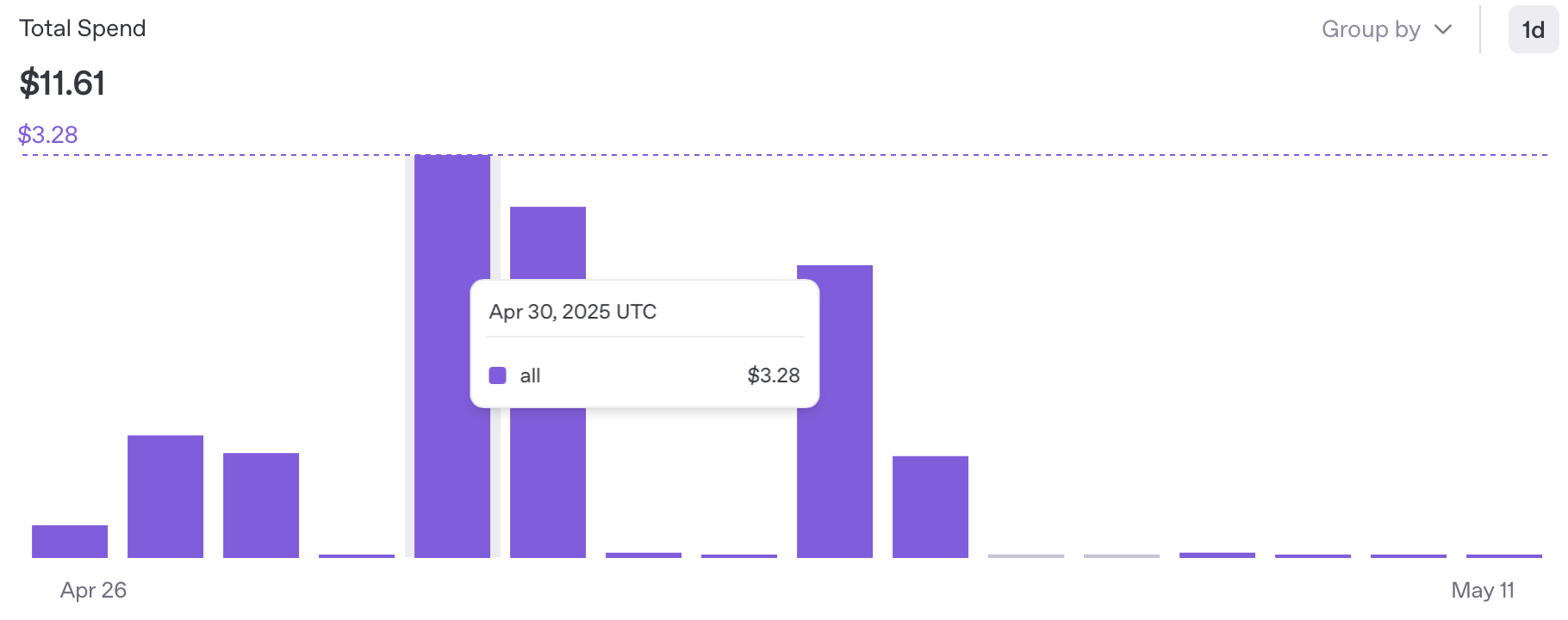
最后,如果是通过 OpenAPI 调用模型,不要忘记定期关注账单和设置阈值
PS. 注意定期 Check 下 API 的费用情况,最近在用使用Jetbains ProxyAI过程中,开启了Enable code completions测试忘记关闭,一周下来发现 OpenAI 每天扣了好几刀,汗~